
[논문 리뷰] Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks
1. 등장 배경
기존 BERT(Cross-encoder)는 STS Task를 해결할 때 두 문장 사이 [SEP] 토큰을 추가해 한번에 입력 처리
이 방법은 두 입력 문장의 self-attention을 통해 높은 성능 기록
하지만 두 문장 사이만의 관계를 확인하는 기존 BERT로 Semantic-Search나 Clustering에 활용하는 것은 매우 비효율적(massive computational overhead)
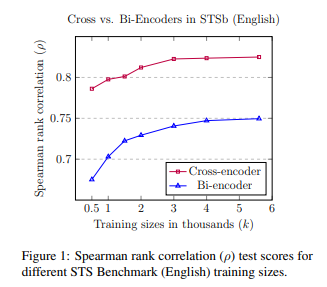
이를 해결하기 위해서 Siamese/Triplet 구조를 활용해 sentence-embedding을 얻을 수 있는 SBERT(bi-encoder)를 제안
SBERT는 BERT에 비해서 낮은 성능을 갖지만 적절한 dense-vector space(sentence-embedding)을 얻기 위해 많은 양의 데이터가 주어진다면 BERT와의 성능 차를 줄일 수 있음
2. 제안
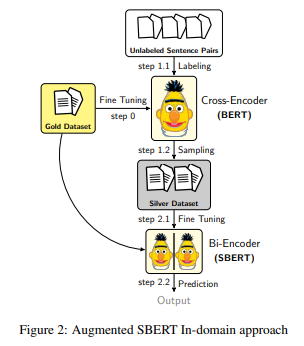
SBERT의 STS 성능을 올리기 위해서 Data Augmentation 진행
- Data Augmentation은 기존 데이터의 모든 sentence를 조합 후 Sampling 하는 방법과 EDA의 SR(Synonym Replacement) 방법 제시
- SR은 WordNet 대신 BERT(Cotextual Embeddings)를 통해서 진행
- 논문에선 Augmented Data를 Silver-dataset, 기존 Data를 Gold-dataset이라고 지칭
Silver-dataset의 Label은 STS 성능이 높은 BERT(Cross-Encoder)로 두 문장 사이 유사도를 계산하여 얻음
- 이때 BERT는 Gold-dataset으로 Fine-Tuning된 상태
최종적으로 기존 Gold - dataset과 Silver-dataset을 모두 SBERT의 입력으로 사용하여 성능 개선
3. 샘플링
Gold-dataset의 모든 sentence를 조합하면 매우 많은 sentence-pair가 생성
이때 Labeling에 BERT(Cross-encoder)가 사용되기 때문에 모든 조합을 사용하면 엄청난 연산량 발생
또한 단순 sentence-pair 조합의 경우 대부분의 경우 유사도가 낮기 때문에(안 비슷한 문장이 당연히 더 많음)
data 분포 측면에서도 적절하지 않음
따라서 적절한 Sampling 기법을 선택하는 것이 매우 중요
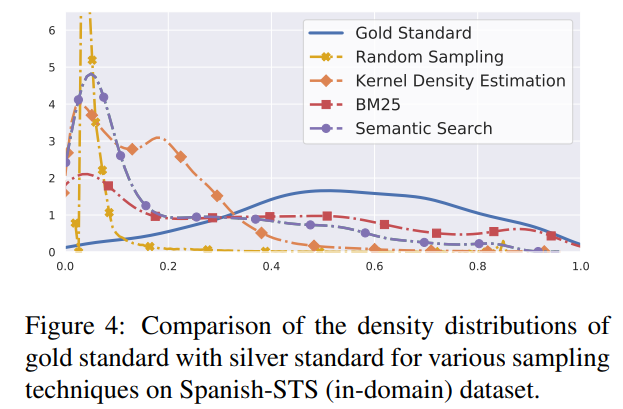
논문에서 제시한 샘플링 별 density distribution은 다음과 같음
1) Random Sampling
문자 그대로 sentence-pair의 일부를 무작위로 샘플링
결국 sentence-pair와 유사한 data 분포를 가져 유사도가 낮은 조합이 많이 선택 됨
가장 낮은 성능 기록
2) KDE(Kernel Density Estimation)
silver-dataset의 분포가 gold-dataset을 따를 수 있도록 scores에 따른 확률 분포 $Q(s)$로 샘플링 진행
유사도가 낮은 sentence-pair를 덜 샘플링하도록 진행
많은 수의 silver-dataset이 생성 됨
$Q(s)=\left\{\begin{array}{cl}1 & \text { if } F_{\text {gold }}(s) \geq F_{\text {silver }}(s) \\ \frac{F_{\text {gold }}(s)}{F_{\text {silver }}(s)} & \text { if } F_{\text {gold }}(s)<F_{\text {silver }}(s)\end{array}\right.$
이때 $F_{gold(s)}, F_{silver(s)}$는 scores $s$에 대한 density function
3) BM25
lexical overlap을 기준으로 하는 BM25 샘플링(Top - 3, 5)
lexical overlap이라는 까다로운 조건 때문에 silver-dataset도 가장 적음
silver-dataset이 적으면 BERT를 통한 Labeling도 최소화되기 때문에 매력적
4) Semantic Search Sampling(S.S)
BM25는 유사한 문장이더라도 lexical overlap이 없으면 검출되지 않는다는 단점 존재
Semantic Search에 이용하면 의미적으로 유사한 sentence를 검출 가능
Semantic Search엔 Gold Dataset에 fine-tuning된 SBERT가 이용
- Semantic Search를 통해서 sentence마다 가장 유사한 Top - 3, 5 조합 구성
5) BM25 + S.S
BM25의 샘플과 S.S의 샘플 결과를 합침
S.S 샘플의 양이 더 많기 때문에 data 분포에 S.S 샘플이 더 큰 영향
따라서 전체적으로 S.S 샘플의 분포를 따르게 됨
lexical overlap을 고려한 BM25의 샘플은 S.S 샘플보다 좀더 유사도가 높은
sentence-pair가 많지만 S.S 샘플에 비해 수가 적기 때문에 영향이 적음
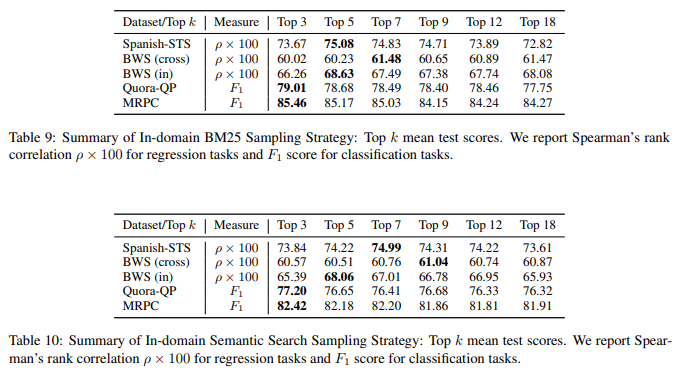
BM25, S.S의 경우 다양한 Top - k로 실험해본 결과 k별로 큰 차이는 없었음
따라서 BERT를 통한 Labeling(inference)를 최소화할 수 있는 k = 3 또는 5로 설정
4. 결과 확인
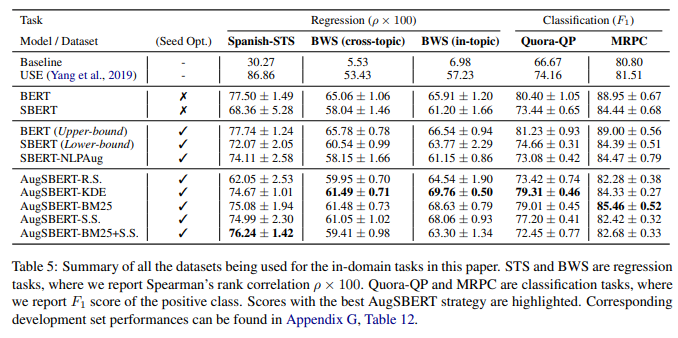
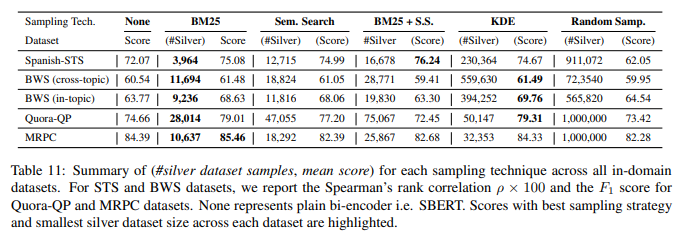
KDE 샘플링이 다양한 Benchmark에서 높은 성능을 기록했지만 BM25와의 격차가 크지 않음
이때 KDE 샘플링은 BM25 샘플링과 비교했을 때 Silver-datasets의 수가 매우 많기 때문에
BERT를 통한 Labeling(inference) 시간을 고려해봤을 때 메리트가 적음
따라서 BM25 샘플링을 활용한 Silver-dataset 생성이 가장 합리적
참고
EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks