
[논문 리뷰] Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text DatasetFor Automatic Image Captioning
|2022. 10. 8. 17:22
MS-COCO의 문제점
COCO 데이터셋엔 그림은 없고, 사진만 있는 등 다양성이 떨어진다. 따라서 데이터가 high correlation을 가지게 된다. 이로인해 아이 사진에 대한 예측 결과를 확인하면 보이지 않는 사물에 대한 문장이 나오는 문제가 발생한다. 또한 파라미터 수가 점점 많아지는 모델들이 사용하기엔 데이터 수가 충분치 않다.

Conceptual Captions
330만 개의 다양한 이미지-텍스트 데이터셋을 만들기 위해, 인터넷에서 얻을 수 있는 정보를 활용해 직접 새로 만들었다. MS-COCO의 문제점을 인식하고 만든 데이터라서 결과는 당연히 더 좋다.
- in front of a building, cake 등의 관련 없는 정보가 더 이상 안나온다.
- 마지막에 서류든 캐릭터를 COCO 데이터에선 볼 수 없기 때문에 animal로 예측했지만, Conceptual에선 cartoon business man으로 예측했다.

파이프 라인
인터넷에서 얻은 데이터를 활용하려면 당연히 필터링이 필요하다. 이를 위해서 이미지 필터링, 텍스트 필터링, 동의어 대체 등의 과정을 진행하는 파이프라인을 구성했다.
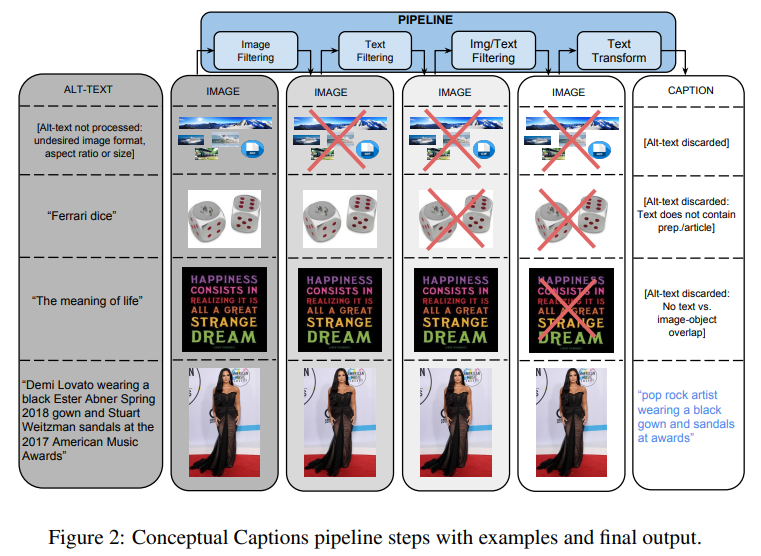
1. 이미지 기반 필터링
- 텍스트에 담긴 의미를 이미지가 최대한 유지할 수 있도록 크기, 비율 값 기준으로 필터링했다.
- 문제될 만한 자극적인 사진도 삭제했다.
2. 텍스트 기반 필터링
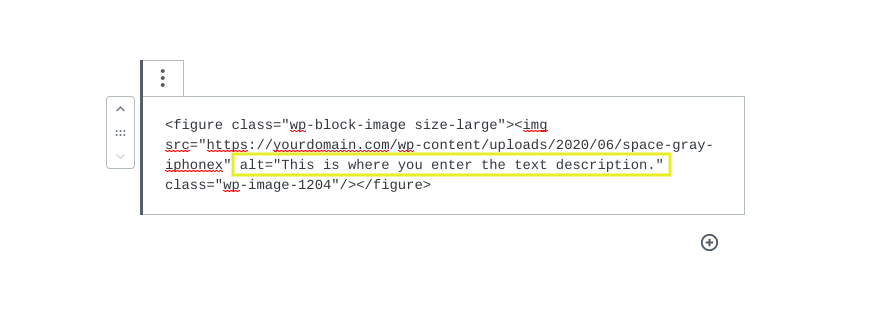
- html의 Alt-tag를 텍스트로 활용
- 휴리스틱한 방식으로 텍스트 필터링 진행
- 다양한 종류의 POS 태그가 담겼는지
- 토큰 반복이 잘 일어나지 않는지
- 첫 문장에 대문자를 활용 했는지, 대문자 비율이 너무 높지는 않은지
- Wikipedea에서 5번 이상 나온 토큰인지
- 자극적 표현이 아닌지
- 기본 문구가 아닌지 ex) 프로필 사진
3. 이미지 + 텍스트 기반 필터링
- 이미지 예측을 통해 라벨 생성
- 생성된 라벨과, 텍스트 사이 stemming 비교 후 겹치지 않으면 제거
4. 동의어로 대체 + 세부 정보 제거

- 고유 명사를 그대로 반영하는 것은 어렵기 때문에 동의어로 대체
- ex) 해리슨 포드 → 배우
- 날짜, 기간, 지명 정보 제거
- 동의어 교체 과정에서 동일한 단어가 나오면, 복수형으로 변경
- ex) 배우와 배우 → 배우들

참고
https://aclanthology.org/P18-1238.pdf