
[논문 리뷰] Sentence-BERT : Sentence Embeddings using Siamese BERT-Networks

1. 등장 배경
STS Task에서 높은 성능을 얻은 BERT는 문장 사이 유사도를 비교하기 위해서 문장들을 [SEP] 토큰으로 분리해 한번에 입력으로 받아 처리
이 방식의 경우 두 입력 문장 사이 유사도를 높은 정확도로 얻을 수 있지만 한 문장과 가장 유사한 문장을 찾는 것은 매우 비효율적(massive computational overhead)
- 모든 경우의 수를 모두 차례로 대입해봐야지만 알 수 있음
한 문장과 유사한 다른 문장들을 찾는 것은 semantic-search, clustering 와 같은 분야에서 다양하게 활용되기 때문에 매우 중요. 이를 효율적으로 해결하기 위해선 정확한 sentence-embeddings를 얻는 것이 관건
sentence-embedding를 얻기 위해서 기존 BERT에서 하나의 문장만을 입력해서 얻을 수 있지만 활용하기에 적절한 embedding이 아님(bad sentence embedding)
2. 제안
good sentence embedding을 얻기 위해서 weights를 공유하는 Siamese/Triplet 구조를 활용한
SBERT 제안
- pre-trained BERT 활용
- 문장 각각 BERT를 통과시킨 후 pooling(MEAN, MAX, [CLS])을 통해서 sentence embedding을 추출
- 추출된 embedidng들을 데이터(Task) 유형에 따라 concat(NLI : classification)하거나 cosine-similarity(STS : regression)를 구하기 위해 활용
SBERT에서 얻은 sentence embedding의 적절성(성능)을 확인하기 위해서 다양한 bench mark 진행
이때 STS에서의 성능 보다는 good embedding인지 보여주는 것을 중점으로 진행
- sentence-embedding 사이 cosine similarity와 Label 간 상관 계수(Spearman) 측정
- STS benchmark
- Argument Facet Similarity(AFS) 스코어
- SentEval 스코어
- Wikipedia Sections Distinction 스코어
3. 모델 구조
Classification Objective
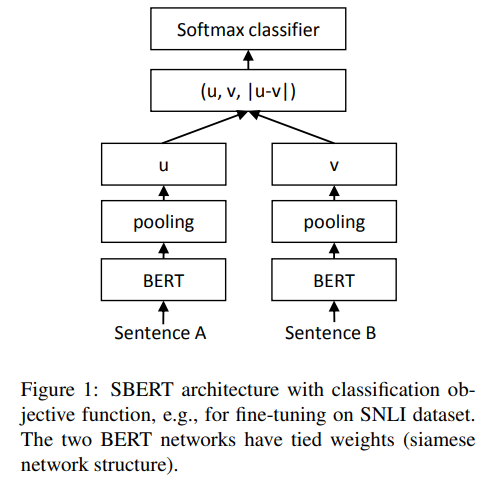
\[Classification objective = softmax(W_t(u, v, |u − v|))\]
$$W_t ∈ R^{3n×k}, n = dim, k = label$$
good embedding을 얻을 수 있다고 알려진 NLI 데이터셋을 입력받아 SBERT fine-tuning
각 문장의 embedidng을 pooling(MEAN, MAX, [CLS])을 통해서 얻음
- MEAN pooling일 때 가장 좋은 결과
embedding을 다양한 조합으로 concat후 Classification 진행
- $u, v, |u-v|$의 조합일 때가 가장 좋은 결과
NLI 데이터셋에 맞게 3 - way Softmax classifier 사용
Regression Objective
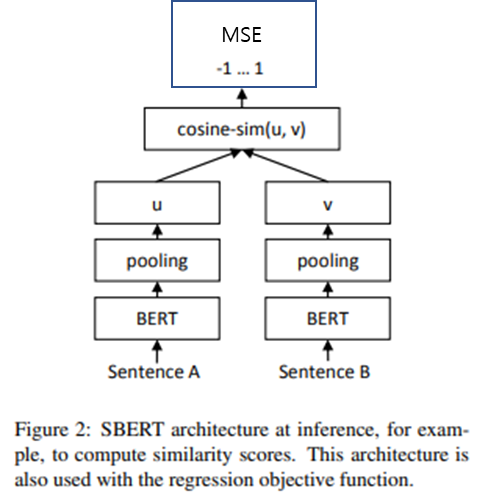
STS 데이터셋으로 fine-tuning하거나 inference할 때 사용
fine-tuning 때 cosine-similarity와 Label(0~1 scaling 필요) 사이의 MSE를 loss function으로 활용
각 문장의 embedidng을 pooling(MEAN, MAX, [CLS])을 통해서 얻음
- MEAN pooling일 때 가장 좋은 결과
Triplet Objective
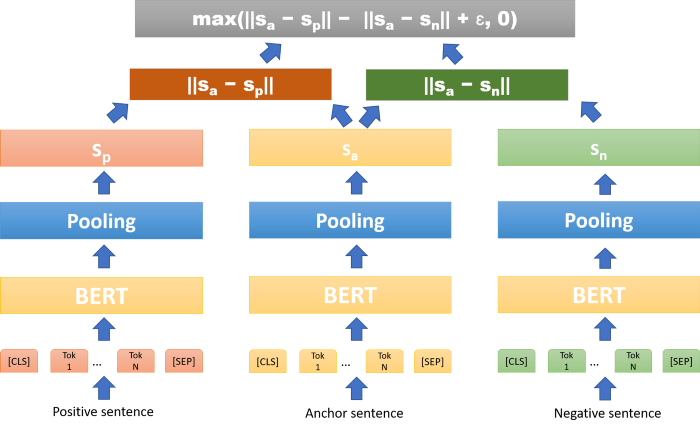
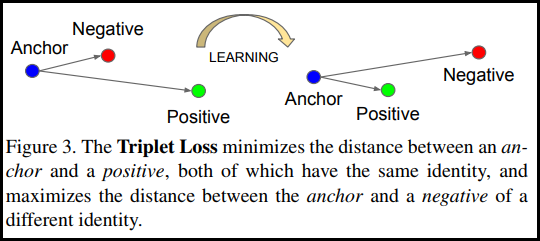
embedding을 얻기 위해서 Wikipedia section triplets dataset (Dor et al., 2018) 활용
- 동일 section이면 Positive, 다른 section이면 Negative로 가정 후 생성된 데이터셋
- $\epsilon$(margin) = 1로 설정
4. 성능 평가
(1) sentence-embedding 사이 cosine similarity와 Label 간 상관 계수(Spearman) 측정
sentence embedding 추출에 적합하다고 알려진 NLI 데이터셋으로 fine-tuning
- 모델이 잘 학습됐다면 아직 보지 못한 다른 문장에 대해서도 good embedding을 얻을 수 있음
good embedding인지를 검증하기 위해서 STS 데이터셋를 활용
- STS 데이터셋의 입력 문장 사이 embedding cosine similarity와 Label간 상관 계수 측정
- good embedidng이라면 similarity와 Label 사이 높은 상관 관계를 가질 것
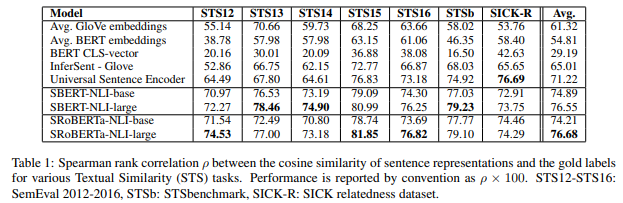
기존 BERT의 경우 매우 낮은 상관 계수 기록했기 때문에 bad embedding을 생성함을 확인
SICK-R의 경우 여러 주제를 다루고 있기 때문에 다양한 데이터셋으로 학습한 Universal Sentence Encoder보다 낮은 점수 기록
평균적으로 SBERT(SRoBERTa)가 가장 높은 점수 기록했기 때문에 좋은 sentence embedding을 얻을 수 있음을 확인
(2) STS benchmark
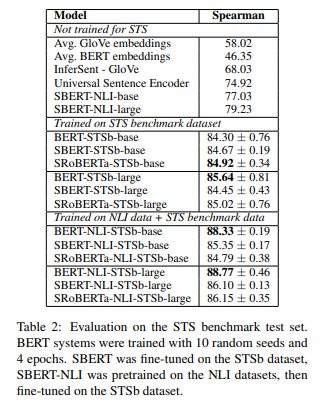
NLI fine-tuning(good embedding) 후 STS fine-tuning 시 가장 높은 성능 기록
두 입력 문장을 한번에 받아 self-attention하는 BERT보단 성능이 낮지만 sentence-embedding 추출만으로도 좋은 성능 달성
(3) Argument Facet Similarity(AFS) 스코어
AFS ?
총기 규제, 동성 결혼, 사형 제도에 대한 찬반 대화를 담은 데이터셋
Topic 마다 다른 어휘가 나오고 주장 및 근거를 모두 고려해야지만 유사도를 판별할 수 있기 때문에
단순 서술 위주의 문장을 가진 STS 데이터셋보다 난이도가 높은 데이터셋
AFS에서의 성능은 10 - fold cross validation과 Cross-Topic으로 확인
- Cross-Topic : 2가지 Topic으로 훈련 후 나머지 Topic으로 테스트
- AFS 데이터의 특성상 새로운 Topic에서 성능을 확인하는 Cross-Topic 방법이 더 난이도가 높음
데이터 예시
Predicted similarities (sorted by similarity):
Sentence A: Eating meat is not cruel or unethical; it is a natural part of the cycle of life.
Sentence B: It is cruel and unethical to kill animals for food when vegetarian options are available
Similarity: 0.99436545
Sentence A: Zoos are detrimental to animals' physical health.
Sentence B: Zoo confinement is psychologically damaging to animals.
Similarity: 0.99386144
[...]
Sentence A: It is cruel and unethical to kill animals for food when vegetarian options are available
Sentence B: Rising levels of human-produced gases released into the atmosphere create a greenhouse effect that traps heat and causes global warming.
Similarity: 0.0057242378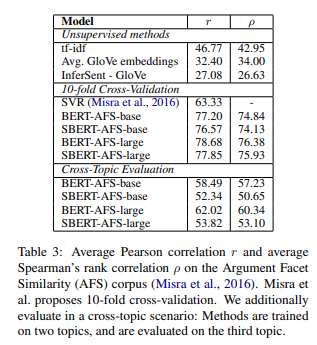
10 - fold에선 SBERT와 BERT 사이 성능이 크지 않지만 Cross-Topic에선 성능 차가 커짐
AFS에선 Topic 마다 sentence 특성이 매우 다르기 때문에 발생
good embedding을 얻기 위해선 sentence 특성이 비슷해야 함을 시사
(4) SentEval 스코어
SentEval?
sentence-embeddings의 적절성을 확인하는 benchmark
embeddings을 이용해 여러 분야의 Classification 문제를 잘 푸는지를 accuracy로 평가
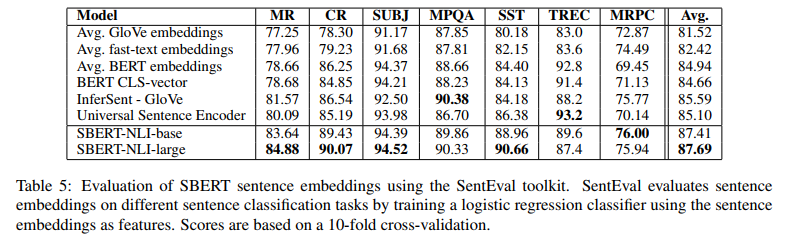
SBERT가 대부분 가장 높은 성능 달성
BERT는 cosine-similarity와 Label 사이의 상관 관계는 매우 낮게 나왔지만 SentEval에선 높은 성능
이를 통해 다음과 같은 추론 가능
- BERT가 추출한 embedding은 dimension 영향을 고려하지 않는 cosine-similarity로는 특성 확인 불가
- Classifer의 경우 특정 dimension이 높고 낮은 영향 가지기 때문에 높은 Accuracy 달성 가능
- BERT의 embedding을 sentence-embedding으로 그대로 사용하기엔 무리
- 기존 BERT의 hidden dimensions은 embedding이라기 보다는 MSE를 최소할 수 있도록 설정 됐다고 할 수 있음
(5) Wikipedia Sections Distinction 스코어
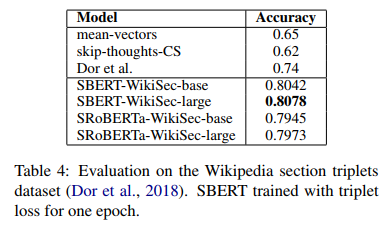
Triplet Objective로 sentence-embedding을 얻을 수 있음을 확인
기존 Triplet Objective를 사용한 Bi-LSTM(Dor et al.)보다 높은 Accuracy 기록
(6) Computational Speed
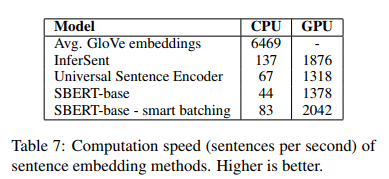
InferSent와 Universal Sentence Encoder보다 좋은 성능을 가졌지만
더 빠른 연산 속도를 가짐
참고