
Abstract
TabNet은 정형 데이터에 적합하도록 설계된 딥러닝 모델이다. TabNet은 Sequential Attention을 통해서 각 decision step 마다 feature(특성)을 선택하고, 이를 통해 트리 모델과 유사한 결정 경계를 가지게 된다.
이는 TabNet이 정형 데이터에 잘 동작할 수 있도록 해주는 inductive bias면서, 동시에 결과 해석과 효과적 학습도 가능하도록 도와준다.
TabNet의 우수성은 여러 벤치 마크에서 기록한 높은 성능을 통해서 확인할 수 있다.
정형 데이터에 흔한 결측치도 self-supervised learning을 통해서 어느 정도 처리할 수 있다는 점도 특징이다.
Introduction
이미지, 텍스트 등의 데이터엔 딥러닝이 많이 사용되는 반면, 정형 데이터에선 주로 트리 기반의 모델을 활용한다. 트리 모델이 많이 활용되는 이유는, 정형 데이터에 더 적합하기 때문이다.
트리 기반 모델이 정형 데이터 처리에 적합한 이유는, 모델의 manifolds(매니폴드)가 정형 데이터의 hyperplane boundaries(결정 경계)에 잘 맞기 때문이다. 추가로 트리 모델을 사용할 경우 결과 해석도 가능하고, 딥러닝 모델과 비교 했을 때 학습도 더 비교적 빠르다는 점도 있다.
트리 모델의 결과 해석은 Feature importance, Tree SHAP 등을 통해서 가능하다고 한다.
자세한 설명은 아래 자료를 참고하면 된다.
[머신러닝의 해석] 2편-(1). 트리 기반 모델의 Feature Importance 속성
[머신러닝의 해석] 2편-(1). 트리 기반 모델의 Feature Importance 속성 Published Mar 29, 2020 <!-- --> 제가 이 Interpretable Machine Learning 시리즈를 포스팅한 계기가 어쩌면 바로 이번 포스트에서 할 내용이라고
soohee410.github.io
Shapley value, SHAP, Tree SHAP 설명
Ensemble Tree로 만족할 수준의 품질을 얻었지만 Black Box 모델의 특성상 예측 결과에 대한 명확한 해석이 쉽지 않았다. 하지만 SHAP(SHapley Additive exPlanation)[1]라는 Machine Learning 모델 해석 기법이 큰 도
daehani.tistory.com
Consistent Individualized Feature Attribution for Tree Ensembles (arxiv.org)
반면 딥러닝은 inductive bias가 적어서, 정형 데이터를 처리를 위해선 과도한 파라미터가 필요하게 되고, 이에 따라 최적해 탐색이 어려워지는 문제가 생긴다. 결국 일반적으로 딥러닝과 정형 데이터는 잘 안 맞다.
실제로 아래의 왼쪽 그림은 모델 별 매니폴드의 형태를 나타낸 것인데, 딥러닝(Neural Networks)의 매니폴드는 트리 모델과 매우 다름을 확인할 수 있다.
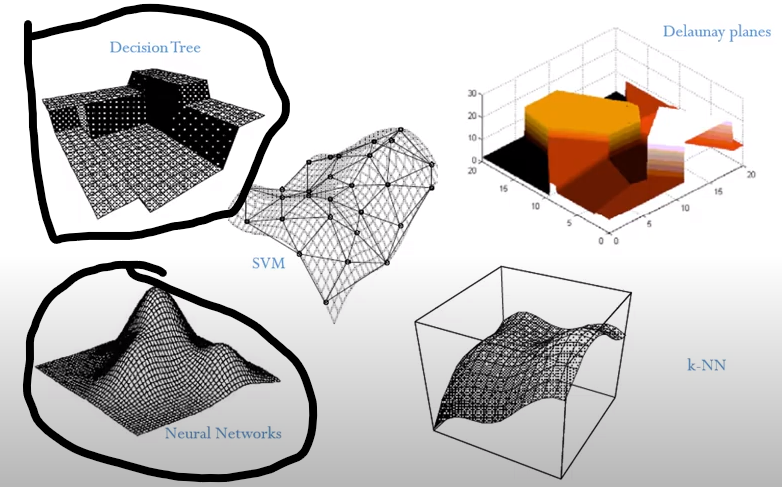
그럼에도 불구하고 딥러닝을 정형 데이터에 적용하려는 이유는, 딥러닝의 장점을 활용하고 싶기 때문이다. 정형 데이터 처리 시, 딥러닝의 기대되는 점을 꼽아보면 다음과 같다.
- inductive bias가 적기 때문에, 많은 데이터를 입력하면 성능이 올라갈 수 있다.
- 정형, 비정형 데이터를 함께 처리할 수 있다.
- Feature Engineering(FE)이 트리 모델 만큼은 필요하지 않을 것이다.
- 계속 유입되는, 스트리밍 데이터를 통해서 학습할 수 있다.
- representation을 얻을 수 있음
- domain adaptation과 generative modeling 등에 활용될 수 있다.
- 다양한 정형 정보와 함께 계산된 representation을 얻을 수 있다면 메리트가 있을 것!
TabNet는 정형 데이터에 적합하도록 설계된 '딥러닝 모델'이기 때문에, 딥러닝의 장점을 그대로 가져갈 수 있어 굉장히 매력적이다. TabNet의 장점과 특징은 다음과 같다.
- TabNet은 입력에 전처리가 필요 없고, 데이터 결측치도 비지도 학습을 통해 처리할 수 있다.
- Sequential Attention을 도입해서, 매 순간 특정 Feature 만 학습할 수 있고, 이를 통해 학습의 효율을 늘리고 모델 해석력을 늘릴 수 있다.
- 매 순간 decision step을 활용한 local 해석과 최종 모델을 활용한 global 해석 모두 가능하다.
- instance-wise한 특성을 추가 모델 없이, TabNet 만으로 가능하다.
일반적으론 instance-wise한 특성을 선택하기 위해 별도의 추가 모델을 활용한다고 한다.
Related Work
전체 데이터를 학습하여 Feature를 선택하는 Global 한 방법이 있고, 이는 Forward(Backward) selection, Lasso 규제 등을 통해 가능하다. 입력 데이터 각각에 대해서 확인하는 instance-wise 방법의 경우, 변수 사이 mutual information을 활용하는 방식이 활용된다. 트리 모델에서 instance-wise 방법을 활용하려면, 별도의 모델을 추가로 활용해야 한다.
위와 같은 방법은 Feature 선택 결과를 통해, Feature를 실제로 추가 - 제거한다. 이런 점에서 Hard Feature selection이라고 할 수 있다.
TabNet는 입력 데이터 단위로 Feature을 선택할 수 있는 instance-wise한 특성을, 추가 모델 없이 학습시 sparsity를 조절하는 방법만으로 가능하다. TabNet에선 Feature가 실제로 선택, 제거 되지 않고, 학습에 따라 결정된다는 점에서 Soft Feature selection이라고 할 수 있다.
Ensemble
트리 기반 모델의 성능을 올리기 위해 주로 트리 + 트리 앙상블을 많이 활용한다. 이 경우 Feature 선택이라는 트리 모델의 특성을 유지할 수 있다. 추가로 트리 + 딥러닝 앙상블 때도 Feature 선택 특성을 유지하면서 성능을 높일 수 있다. 실제로 TabNet과 기존 트리 모델을 앙상블 했을 때 성능이 꽤 잘 나왔다고 한다.
Integration of DNNs into DTs
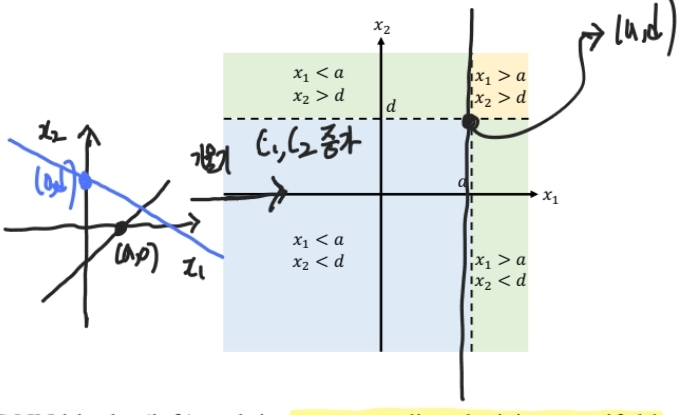
트리 모델은 결정 경계가 수직으로 그어지는데, 이는 Feature 선택(0 또는 1로 생각) 때문이다.
딥러닝으로 트리 모델와 유사한 결정 경계를 만들어, 비슷한 특징을 같도록 하는 다양한 시도들이 있었고, 결론만 말하면 잘 안 됐다. 추가적인 refinement 작업 없이 Feature를 선택하는 것이 쉽지 않았다.
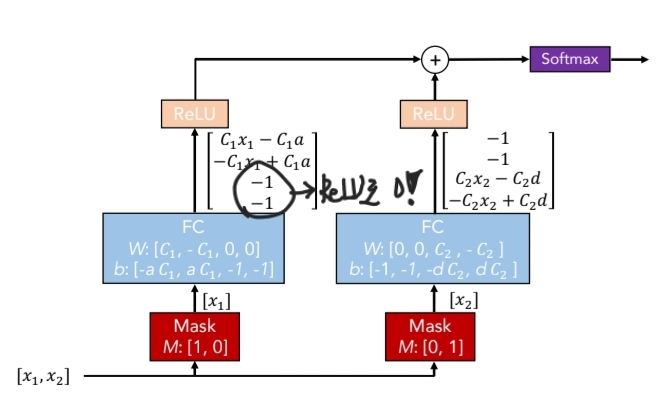
딥러닝으로 트리와 유사한 결정 경계를 만들기 위해선, 우선 각 성분에 의한 직선을 그릴 수 있어야 한다. 이를 위해 Mask를 사용하고, ReLU로 불필요한 성분의 값을 0으로 변경한다. 이 경우 weight를 기울기로 하고, bias를 절편으로하는 직선을 만들 수 있고, 그 직선의 기울기 $C1, C2$가 매우 크다면 결국 수직인 결정 경계를 얻을 수 있게 된다.
수직 경계를 얻기 위한 과정을, Masking된 성분을 ReLU 함수에 통과 시킨 뒤에 합하는 것으로도 볼 수 있다. 이는 TabNet에서 $d_{out}$를 구할 때, $\sum$ReLU($d_i$) 합을 하는 이유가 된다.
TabNet for Tabular Learning
TabNet을 통해 정형 데이터를 다룰 경우 다음과 같은 특성이 있다.
1. 학습을 통해 instance-wise한 Feature 선택을 할 수 있다.
딥러닝으로 트리와 비슷한 결정 경계를 만들기 위해선, Mask를 통해 Feature를 고르고, weight의 $C1, C2$를 업데이트 해야 한다. 이때 weight의 업데이트는 입력된 데이터에 의해 가능하기 때문에, 결국 TabNet은 instance-wise한 Feature 선택을, 별도의 추가 모델 없이도 할 수 있게 된다.
2. Sequential multi-step 구조를 활용하기 때문에, 각 step에서의 local Feature 기여도와 Global Feature 기여도를 확인할 수 있다.
기여도 분석엔 Feature 선택에 활용한 Mask를 활용한다.
Mask의 가중치는 고정되지 않고, 학습에 따라 변한다.
- Local : $M[i]$를 통해서 확인 가능
- Global : $M_{agg}$를 통해서 확인 가능
3. 일종의 앙상블 효과를 얻을 수 있다.
Seqential multi-step 구조를 통해서, 이전 step이 다음 step에도 영향을 주기 때문이다.
또한 입력 데이터를 embedding하여 활용한다는 점도, 앙상블 효과를 내는데 도움을 준다.
- dense 벡터인 embedding엔, 이전 및 전체 step의 다양한 정보가 저장될 것이기 때문이다.
- 실제로 Feature Transformer엔 step dependent와 shared 성분이 있다!
Encoder only
TabNet은 Encoder만 사용해서 정형 데이터를 처리할 수 있다.
전체 과정을 그림으로 정리하면 아래 그림과 같다.
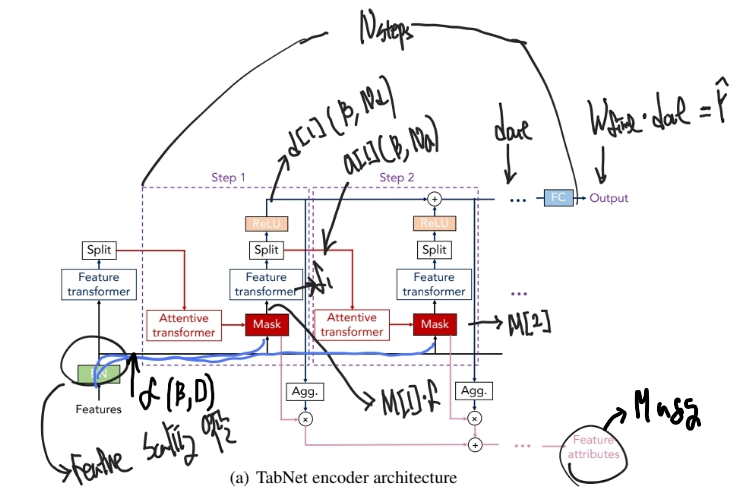
각 과정에서 중요한 부분을 따로 확인해보자.
1. 입력 데이터 처리
- 범주형, 수치형 Feature를 Embedding 하여 $f$ : $(B\times D)$를 얻는다.
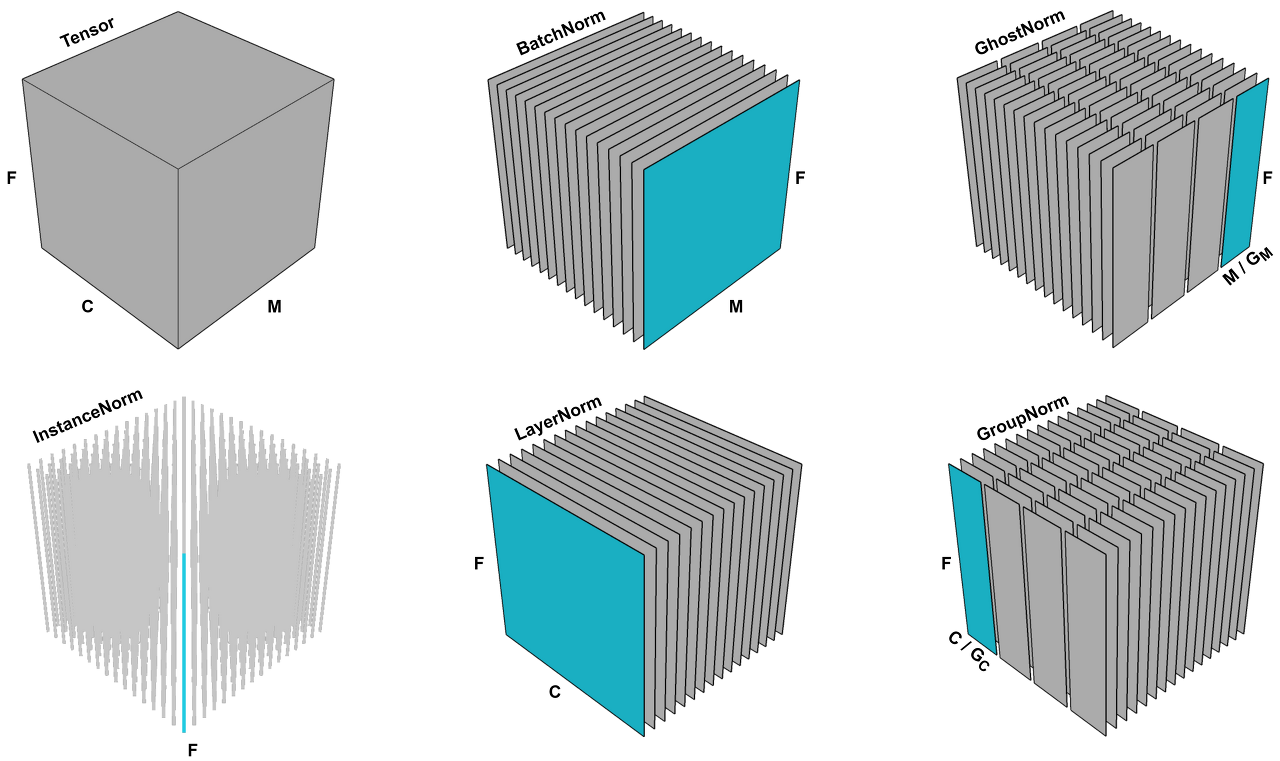
- Embedding 전에 수치형 데이터는 Batch Normalization(BN)을 활용해서 Scaling을 한다.
- Feature Transformer, Attentive Transformer에선 빠른 학습을 위해 Ghost BN을 활용 하지만, 입력 데이터에 대해선 BN을 활용한다.
- 이는 BN이 Ghost BN에 비해서 N이 커서, 데이터의 분산을 더욱 작게 유지할 수 있기 때문이다.
2. Feature processing
Feature $f$를 Feature Transformer에 입력하여, decision embedding$d[i]$와 processed feature$a[i]$를 얻는다.
$d[i]$는 최종 출력인 $d_{out}$ embedding을 얻기 위해 활용되고, $a[i]$는 다음 step의 Masking에 영향을 준다.
$$d_{out} = \sum_{i = 1}^{N_{steps}}ReLU(d[i])$$
$d_{out}$는 위 식과 같고, $d[i]$의 성분들을 ReLU 통과 시킨 뒤 합해서 얻는 것을 확인할 수 있다. 이렇게 하는 이유는, 트리 모델처럼 수직인 결정 경계를 가지기 위해서다.
- 현재 포스팅의 Integration of DNNs into DTs 부분을 참고 → Related Work 부분에 있음
Feature Transformer

- Feature $f$를 변형하여 processed Feature인 $a[i]$와 decision step에 사용할 $d[i]$를 얻는다.
- $GLU = x\cdot \sigma (x)$를 도입해 $f$에서 필요한 정보를 필터링한다.
- 각 step 마다 파라미터가 공유되는 부분(Shared across)과, 공유 되지 않는 부분(Step dependent)이 있다.
- 파라미터 공유를 통해, 특정 step 결과에 의해 $f$가 크게 변하지 않는 특징(robust)이 있다.
- 안정적인 학습을 위해 Residual Connection 결과에 $\sqrt {0.5}$를 곱해서, 분산이 절반이 되도록 했다.
- 왜 하필 절반인지는 인용된 Convolutional Sequence to Sequence Learning 논문에도 안 나와 있는 듯?...
3. 학습 가능한 마스크 $M$을 활용한 Feature 선택
$M$이 데이터에 의해 학습 되기 때문에, 결국 instance-wise한 Feature 선택이 가능해진다.
$M[i]$의 합은 항상 1로 고정되기 때문에, $M$를 활용하면 local Feature 기여도를 확인할 수도 있다.
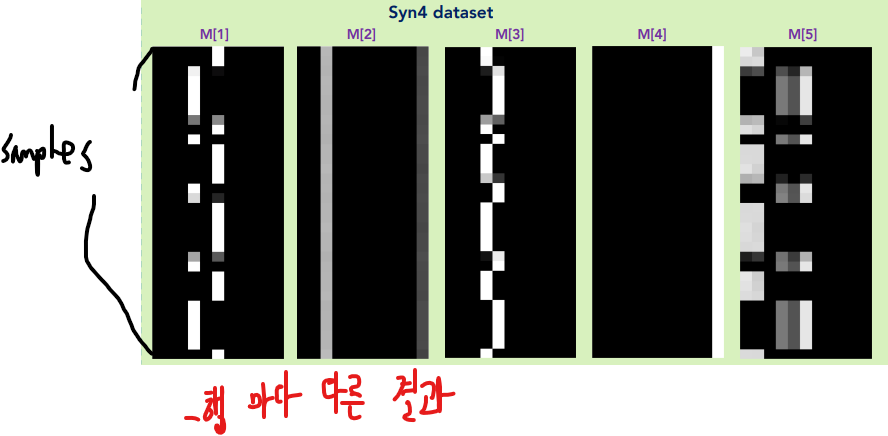
$M$을 통해 Feature를 선택(마스킹)할 경우, 불필요한 특성에 모델의 capacity가 낭비되지 않도록 돕는다는 점에서, 파라미터를 효율적으로 관리할 수 있도록 도와준다. $M$은 $f$ 크기에 맞도록, $M$ 또한 $(B\times D)$의 크기를 가진다.
- 마스킹은 $M[i]\cdot f$를 통해서 한다.
Attentive Transformer
$M[i]$를 얻기 위해 활용되는 것이 바로 Attentive Transformer이다.
Attentive Transformer의 구조는 아래와 같다.
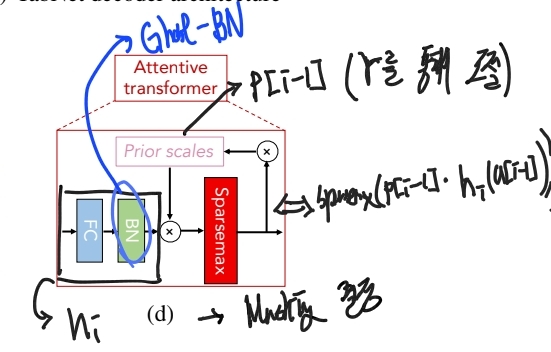
$M[i] = Sparsemax(P[i - 1]\cdot h_i(a[i - 1))$으로, $M[i]$는 $P[i-1]$와 $a[i-1]$에 의해서 결정 되는 것을 확인할 수 있다.
- $a[i -1]$를 통해 이전(step dependent) 및 전체 step(shared)의 Feature Embedding이, 현재의 마스크 결정에 영향을 준다는 것을 확인할 수 있다.
- $P[i -1]$를 통해 이전 step에서의 Masking 정보가, 현재의 마스크 결정에 영향을 준다는 것을 확인할 수 있다.
Prior Scaling
$$P[i]=\prod_{j=1}^{i} (\gamma-M[j])$$
$P[i]$는 prior scaling을 뜻하고, 수식으로 정리하면 위와 같다.
수식을 보면, 현재 step $i$ 에서의 $M{j, b}$가 0이 아닐 경우, 나중 step에서의 $P$는 점점 작아 질 것이라는 것을 확인할 수 있다. P가 작아지면 $M[j]$는 점점 덜 선택될 것이기 때문에, 결국 $P[i]$는 '새로운 Feature를 얼마나 탐색할 지 결정'하는데 기여하게 된다.
탐색 정도는 $\gamma$를 통해 결정되고, 이는 Feature의 sparsity와도 관련이 있다. 실제로 만약 $\gamma$가 1이라면, 한번 활용된 특성은 더이상 활용되지 않고, 매번 새로운 특성만 활용하게 될 것이다. 이에 따라 Feature는 sparse해질 것이다.
반면 $\gamma$가 1보다 크다면, 앞서 사용된 특성이 여러번 활용될 수 있다.
Sparsemax
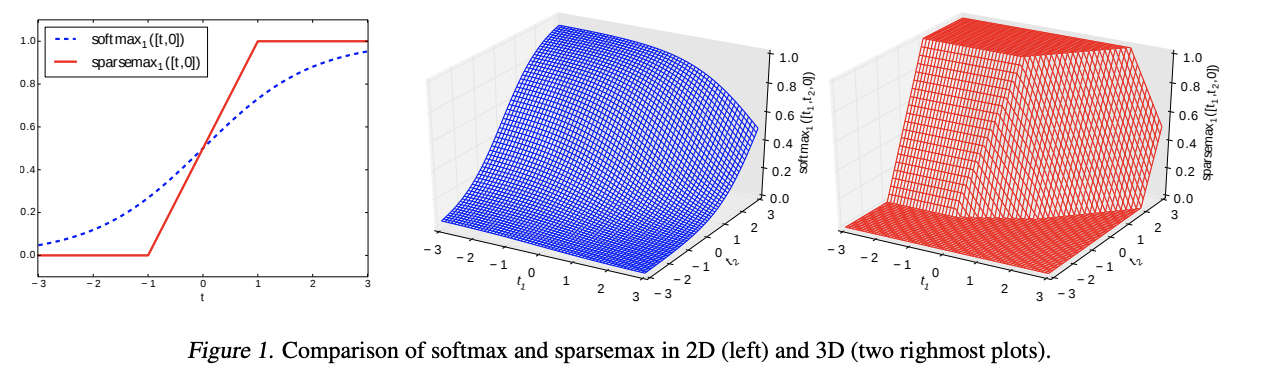
Attentive Transformer엔 Sparsemax가 있고, 이를 통해 local Feature 기여도를 분석할 수 있게 된다.
sparsemax는 softmax의 일종으로, 반환 값의 총 합이 1이 되도록 정규화하는 역할을 하기 때문이다.
sparsemax는 softmax에 비해 0, 1로 빠르게 수렴하는 특성이 있고, 이는 sparse한 Feature 선택에 도움을 준다.
Sparsity Loss
TabNet이 효율적으로 학습하고, 결과를 해석하기 위해선 sparse한 Feature 선택이 중요하다.
이를 위해선 Loss 항에 sparsity 규제 항을 포함 시킨다. 규제 항의 계수는 $\lambda_{sparsity}$로, 이를 통해 spasity를 조절할 수 있다.
sparsity 규제 항은 $M_{b, j}$의 entropy를 통해서 계산된다.
entropy는 0 또는 1 일 때 최소가 되기 때문에, 결국 Loss를 줄이기 위한 학습이, sparse한 Feature 선택에도 도움을 주게 된다.
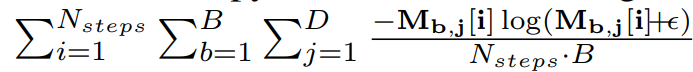
4. $\hat {y} = W_{out} d_{out}$
$\hat {y}$는 $d_{out}$과 $W_{out}$를 통해서 구할 수 있다.
최종적으로 $W_{out}$의 출력에 따라 회귀, 분류 모델 여부가 결정 된다.
5. $M_{agg}$를 도입해 Global한 Feature 기여도 파악
$\hat {y}$에 $d_{out}$이 활용 됐으니, $d_{out}$을 구성하는 $d_i$를 통해 각 step의 기여도를 파악할 수 있을 것이다. 이를 위해 $\eta_b[i]$를 도입한다. $\eta_b[i]$를 식으로 나타내면 아래와 같다.
$$\eta_b[i]=\sum_{c=1}^{N_d} ReLU(d_{b,c}[i])$$
$b$는 $b$ 번째 샘플을 의미하기 때문에, $M_{b, j}[i]$와 결합하면 각 step에서 $j$ Feature의 기여도를 확인할 수 있게 된다. 이를 $M_{agg-b,j}$라고 하며, 수식으로 나타내면 아래와 같다.
$$M_{agg-b,j}={ \sum_{i=1}^{N_{steps}} \eta_b[i]M_{b,j}[i] \over \sum_{j=1}^D \sum_{i=1}^{N_{steps}} \eta_b[i]M_{b,j}[i]}$$
분모의 $\sum_{j=1}^{D}$ 항 덕에, 총 합이 1이 되도록 정규화된 값을 얻게 된다.

Self-supervised Learning : Encoder + Decoder
Encoder와 Decoder를 활용한 Self-supervised Learning를 통해 결측치를 처리할 수 있다.
하지만 이것이 결측치를 알아서 채운다는 것을 의미하지는 않는다.
그보다는 결측치가 좀 더 의미를 가질 수 있도록 도와주는 역할을 한다.
따라서 결측치가 있어도 모델이 어느 정도 성능이 나올 수 있도록 도와주는, 일종의 pretraining 기법으로 보면 된다.
Self-supervised Learning 전처리?
nunique = train.nunique()
types = train.dtypes
categorical_columns = []
categorical_dims = {}
for col in train.columns:
if types[col] == 'object' or nunique[col] < 200:
print(col, train[col].nunique())
l_enc = LabelEncoder()
train[col] = train[col].fillna("VV_likely") # 결측치 채우기(카테고리형)
train[col] = l_enc.fit_transform(train[col].values)
categorical_columns.append(col)
categorical_dims[col] = len(l_enc.classes_)
else:
train.fillna(train.loc[train_indices, col].mean(), inplace=True) # 결측치 채우기(수치형)위 코드는 Self-supervised Learning에 활용할 데이터를 전처리하는 코드다.
코드를 확인해보면 전처리 과정에서 이미 결측치를 채운다는 것을 확인할 수 있다.
결국 임의로 채운 값의 Feature $f$(Embedding)가 더 의미 있게 도와주는 것이, 바로 Self-supervised Learning의 역할이다.
Decoder
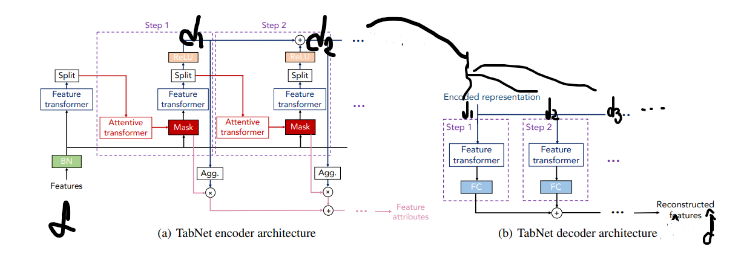
입력 Feature를 $f$라고 한다면, Encoder와 Decoder를 통해 복원한 Feature를 $\hat f$이라고 한다. 결국 $f$와 최대한 유사한 $\hat f$를 얻는 것이 목적이다.
Decoder엔 Encoder의 각 step의 출력인 $d_i$가 입력되고 이를 Feature Transformer과 FC Layer에 통과 시킨다.
최종적으로 각 step에서 얻은 FC Layer의 출력들을 합하는 방식(torch.add)으로 $\hat f$를 얻는다.
Binary Masking
Self-supervised Learning은 Feature $f$를 Decoder의 출력 $\hat {f}$를 통해서 복원하는 방식으로 이뤄진다.
이 과정을 통해 결국 결측치 정보를 주변 데이터를 통해서 채울 수 있다.
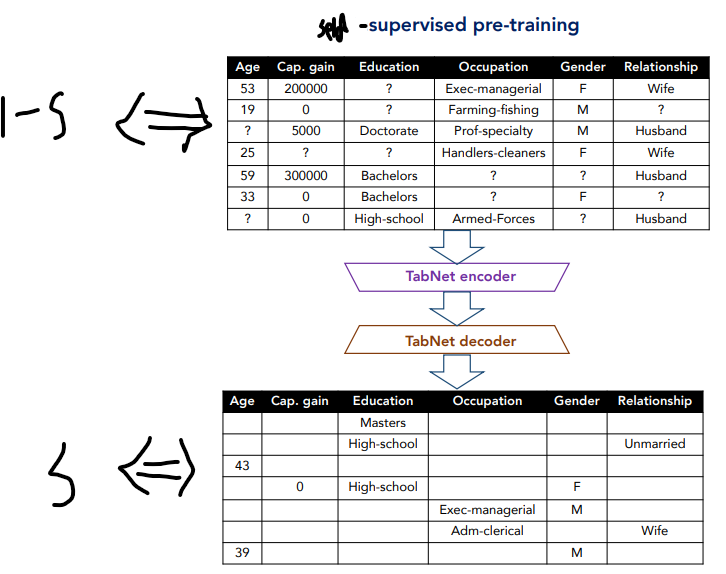
주변 데이터를 통해 Feature를 학습하기 위해선, Decoder와 Encoder가 서로 다른 성분 ${b, j}$를 참고해야 할 것이다. 이를 위해 데이터에 binary Mask를 도입하고, Decode와 Encoder가 서로 반대가 되도록 설정한다. binary Mask를 $S_{b, j}$로 설정한다면, 결국 Decoder는 $S$를, Encoder는 $1 - S$인 Mask를 가지게 될 것이다.
이때 Decoder는 Attentive Transformer가 없어서 Mask $S$를 그냥 적용하면 되지만, Encoder는 별도의 $M$이 존재한다. 그래서 Encoder에선 step이 늘어날 수록 $S$ 영역을 참고하지 못하도록, prior scaling $P[0]$를 $1 - S$으로 설정하여 $1 - S$와 같은 Mask를 가지도록 유도한다.
Mask $S_{b, j}$는 고정된 상수가 아니라 베르누이 분포($p_s$)를 따르는 확률 변수이다. 따라서 매 iteration 마다 다른 $S_{b, j}$를 사용한다. 이를 통해 epoch가 늘어날 수록 다양한 Mask 영역을 참고(매번 다른 위치 조합)하게 되고, $f$와 $\hat {f}$는 점점 유사해질 것이다.
- $S$를 결측치 영역에만 따로 적용하는 것이 아님! → 이미 결측치는 채워 둔 상태
- 결측치 정보를 저장해뒀다가, 해당 영역에 가중치를 주는 방법도 고려할 수 있을 듯?
Self-supervised Loss

$f$와 유사한 $\hat {f}$를 얻기 위해서 사용되는 Loss 함수이다.
각 컬럼 $j$ 마다 범위가 다를 수 있기 때문에, 예측할 $f_{j}$의 표준 편차를 통해서 Scaling 하는 것을 확인할 수 있다.
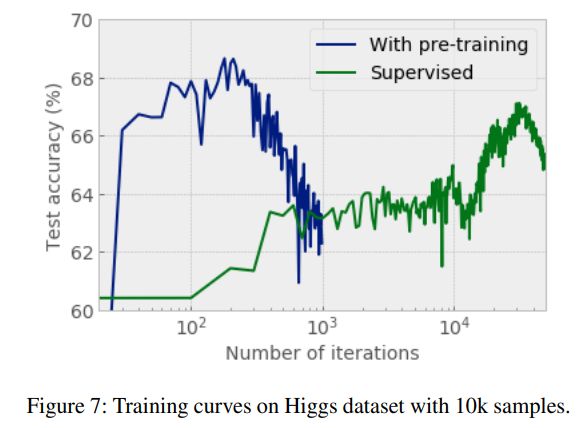
Self-supervised Learning의 효과?
앞서 self-supervised Learning이 일종의 pre-training 역할을 한다고 했었다.
Self-supervised Learning(With pre-training) 후엔, 기존 Encoder(Supervised)만 사용한 경우에 비해 보다 빠르게 수렴하는 것을 확인할 수 있다.
Hyperparameter 튜닝 가이드
TabNet의 주요 하이퍼 파라미터와 튜닝 가이드를 정리하면 다음과 같다.
$N_a$ ($a[i]$의 Embedding 크기), $N_d$ ($d[i]$의 Shape)
- $N_a$는 모델의 complexity과 $N_d$는 모델의 성능과 관련
- 일반적으로 $N_a = N_d$로 설정
$\gamma$ (Prior scaling 결정), $\lambda_{sparse}$ (sparsity Loss의 계수)
- $\gamma$는 $N_{steps}$과 비례하게 설정하면 좋음(크면 크고, 작으면 작게)
- 너무 작지 않은 $\gamma$와 너무 크지 않은 $\lambda$를 조합하여 sparsity를 조절
$N_{steps}$ (Decision step의 수)
- 정보를 뽑아내고 싶은 Feature가 많은 편이라면 $N_{steps}$를 늘리자
- 너무 늘리면 Gradient가 업데이트 되지 않을 수 있기 때문에 주의해야 함
$B$ (Batch size)
- Ghost BN을 활용하기 때문에, 매우 큰 B를 사용해도 됨
- 가능하면 학습 데이터 크기의 1% ~ 10% 정도로 설정하는 것을 추천
Feature Transformer Block
- 1개의 Shared Block 만으로 구성된 Feature Transformer를 사용해도 꽤 좋은 성능을 유지한다.
- 이는 Sequential decision(=Masking + $d[i]$)이라는 inductive bias가 TabNet의 핵심이라는 것을 알려준다.
참고