
Abstract
대규모인 유튜브 환경에서 추천을 진행하기 위해 2 - stage information retrieval을 이용하여 추천 시스템을 구성하였다.
이때, 각 과정에 딥러닝을 활용했으며 2 - stage는 각각 다음과 같다.
- candidates generation 과정
- ranking 과정
Introduction
유튜브에선 많은 유저(10억 단위)들에게 실시간으로 업데이트 되는 영상을 추천해야 하며, 이는 다음의 3가지 측면에서 challenging하다.
- Scale : 기존 추천 방식(Matrix Factorization)은 유저 - 콘텐츠가 매우 많은 유튜브에서 사용할 수 없다. 유튜브 추천 시스템은 실제 서빙 환경인 분산 처리 환경에서 잘 작동해야 한다.
- Freshness : 새로 업로드된 영상과 기존 유저 취향을 적절하게 고려해야 하며 이는 exploration/exploitation 사이의 균형이 필요하다는 것을 의미한다.
- Noise : noisy한 데이터의 특성을 고려하여 robust한 추천을 진행해야 한다.
- 유저 행동 데이터의 특징
- 기본적으로 sparse하며 측정할 수 없는 외부 요소들에 영향을 받아 예측에 그대로 사용하긴 힘들다.
- 좋아요, 구독과 같은 explicit feedback은 long-tail 문제를 해결할 수 없기 때문에 implicit feedback으로 모델링을 진행해야 한다.
- 콘텐츠 데이터의 특징
- 메타 데이터가 존재하지만 ontology라 볼 수 없고 퀄리티가 매우 낮다.
- 유저 행동 데이터의 특징
System Overview
2 - Stage로 추천을 진행하며 이를 통한 이점은 다음과 같다.
- millions 단위의 영상 풀에서도 개인화된 추천을 구성할 수 있다.
- ranking에 넣어줄 후보들을 다른 candidates sources에서도 활용 가능하다.
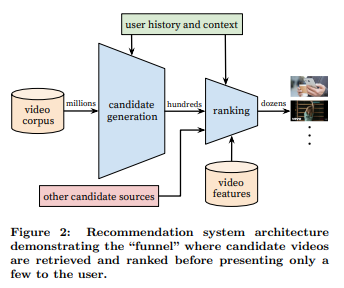
candidates generation
- 유저의 시청 기록과 demographic 정보 등을 통해서 추천 후보를 millions에서 hundreds로 줄이는 과정이다.
- 높은 precision을 가지도록 추천 후보 구성하는 것이 목표다.
- 보고 싶은 영상을 추천해주지 않는 것(FN)보다 보기 싫은 영상을 추천하지 않는 것(FP)이 더 중요하기 때문!
ranking
- 최종적으로 유저에게 보여줄 dozens 단위의 추천을 구성하는 단계이다.
- 필터링이 된 영상들이기 때문에 recall이 중요하다.
- 유저와 영상에 대한 다양한 특성들이 활용된다.
- 최종적으로 유저가 좋아할만한 영상을 얻는 단계이다!
Candidates Generation
Training
- 유저 행동 임베딩(watch, search)과 유사한 영상을 찾는다는 측면에서 일종의 non-linear matrix factorization으로 생각할 수 있다.
- $v_iu$가 높은 $v_i$를 찾는 과정
- 추천을 클래스 종류가 매우 많은 다중 분류로 접근한다.
- 다중 분류로 접근하게 되면 특정 시점 $t$에서의 가장 높은 확률을 가지는 영상 $w_t$를 유저/컨텍스트에 따라 결정하는 것과 동일하며 이를 수식으로 표현하면 다음과 같다.
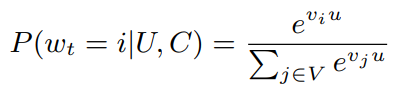
- 이때, $u$와 $v$ 모두 $\mathbb{R}^{n}$이므로 학습을 통해 $vu$를 잘 표현할 수 있는 임베딩을 구성하게 됨
- $w_t$에서의 softmax를 구하는 과정에서 영상이 M개라면 $O(M)$의 시간 복잡도가 발생하는데 M이 매우 큰 유튜브 scale에서는 연상량이 매우 커짐
- 따라서 softmax를 구하는 과정을 최적화해야 하는데 논문에선 negative sampling을 이용해 이진 분류 문제로 바꿔서 해결했다.
- 이때, hierchical softmax로 접근하는 방법도 있지만 이 경우 tree 구조로 변경하면서 관련 없는 클래스들이 묶이는 단점이 있어 성능이 좋지 않았기 때문에 선택하지 않았음
Inference(Serving)
- Serving을 통해 최종적으로 Top-$N$개의 candidates를 구성해야 한다.
- 클래스 별 점수를 계산해주는 Softmax는 연산량이 매우 커서 사용하지 않았고, 대신 $\mathbb{R}^{n}$에서 $u$의 nearest neighbor $v$를 찾는 방법을 활용했다.
- 이때 빠른 탐색을 위해 근사 기법을 사용했다. A/B 테스트 결과 근사 기법의 종류는 결과에 별 영향을 주지 않았다.
- faiss와 같은 패키지를 활용할 수 있다.
Candidates generation 구조
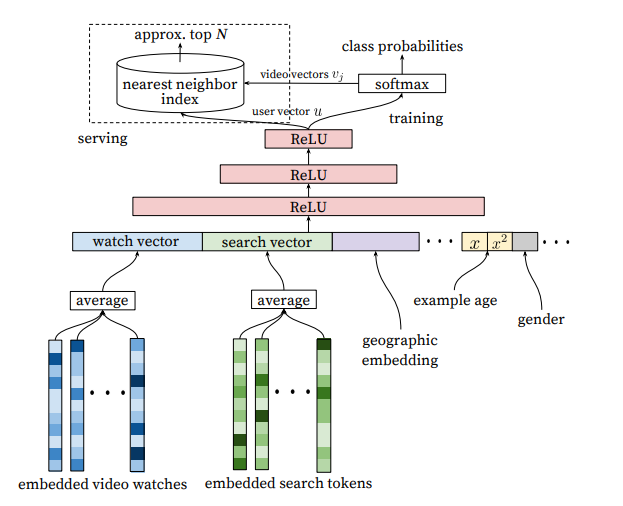
- 유저가 시청한 영상(ID) 임베딩을 average하여 고정된 차원의 watch vector 구성
- 유저가 검색한 tokens들의 임베딩을 average하여 고정된 차원의 search vector 구성
- 새로운 유저에게 추천을 하기 위해서 Demographic 정보 활용
- geographic region과 devices 정보는 임베딩 추출
- 유저의 성별, 로그인 정보, 나이 같은 정보는 $[0, 1]$로 정규화하여 활용
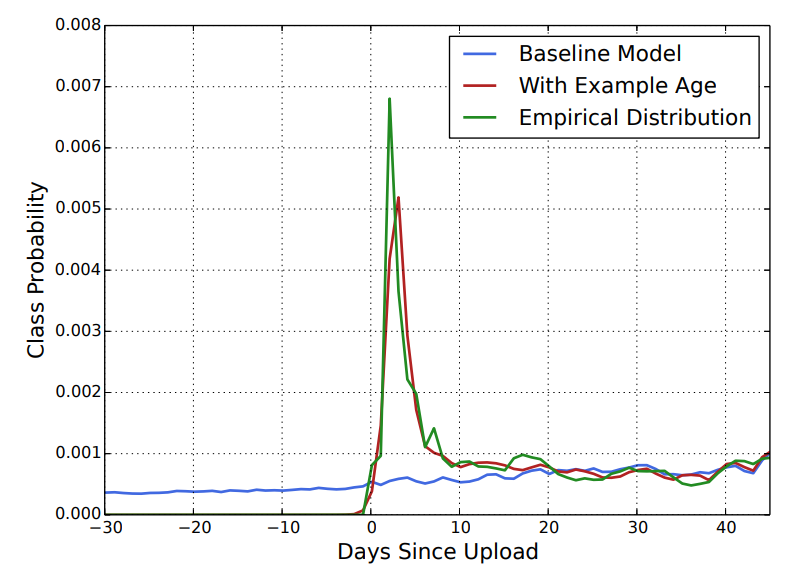
- 유저는 자신의 취향과 비슷한 영상일 경우 최신 영상을 선호하기 때문에 example age를 도입해 최신 영상에 가중치 부여
- 최신 영상에 가중치를 부여하게 되면 원래는 선택되지 않을 새로운 영상들이 추출 된다. 이는 곧 일종의 bootstrapping 역할을 하며 동시에 viral content를 확산 시키기에도 유리하다.
- 실제로 example age를 도입할 경우 경험적으로 얻은 분포와 매우 비슷해짐을 확인할 수 있다.
Surrogate Problem 설정
- 훈련에 사용되는 데이터는 추천 알고리즘을 거치지 않고 유튜브 영상에 접근하는 경우도 포함하기 때문에 exploitation뿐만이 아니고 exploration도 고려해야 한다.
- 헤비 유저의 과도한 영향력을 제한하기 위해서 유저 별 Training Samples 개수를 동일하게 설정한다.
- 시리즈 작품의 경우 동시 시청될 확률이 매우 높기 때문에 random hold-out을 통해 추천할 경우 정확도가 매우 떨어진다. 시리즈 작품의 존재를 고려하면 유저가 다음에 시청할 영상을 추천하는 것이 더 적합한 Surrogate Problem이다.
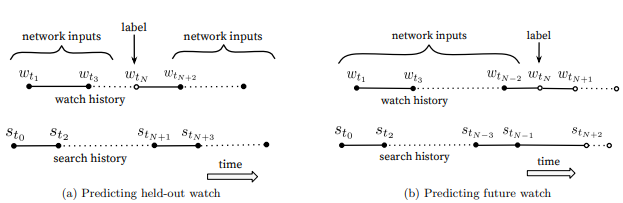
- hold-out 추천의 경우 미래 정보를 활용할 수 있다는 점에서도 Surrogate Problem으로 설정하기엔 문제가 있다.
실험 결과 확인
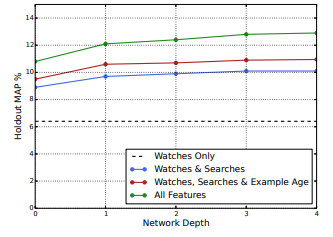
- 네트워크 구조는 MLP이며 Layer 수가 증가할 수록 MAP가 증가했다.
- 시청 정보만 확인할 때 보다 특성들을 추가할수록 성능이 증가했다.
Ranking
Ranking 단계에선 후보 영상의 수가 100개 단위로 줄어들기 때문에 좀 더 다양한 유저와 영상의 특성을 활용할 수 있다.
A/B 테스트 결과 CTR 예측 보다는 시청 시간(watch time)을 예측하는 것이 더 나은 추천 결과를 얻었다고 한다. 썸네일 낚시 같은 경우를 생각하면 일리가 있다.
YouTube Now: Why We Focus on Watch Time
blog.youtube
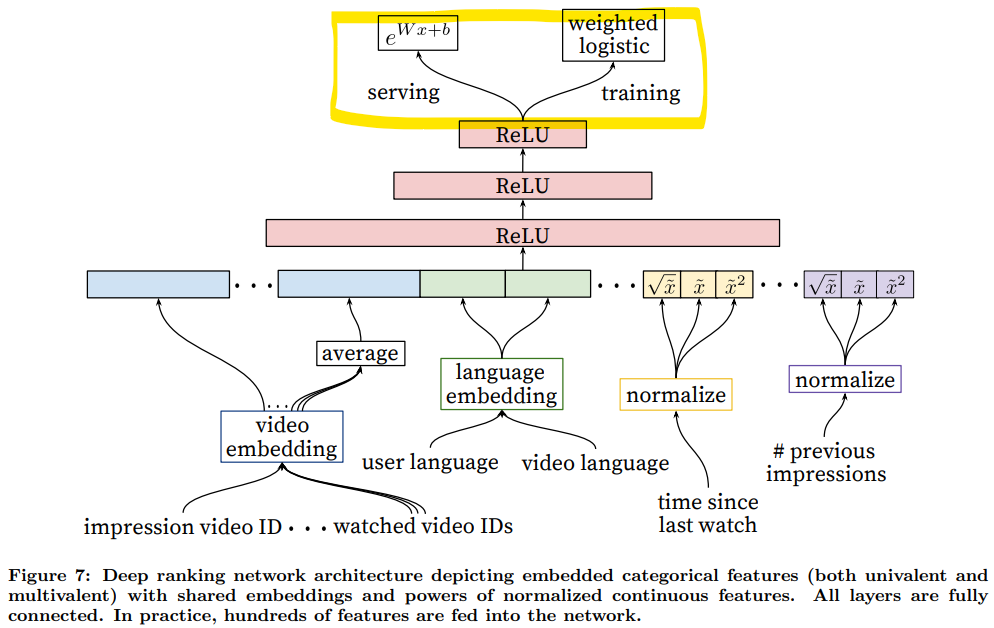
Feature Engineering(FE)
- 특성을 형태(categorical/continuous/ordinal)에 따라서 또 영향(univalent/multivalent)에 따라서 분리했다. 구체적으로 어떻게 활용 했는지와 결과에 대한 언급은 없지만 의미있던 접근법이었던 거 같다.
- FE를 통해서 100 여개의 특성을 활용했다고 하는데 논문에서 언급된 의미있는 특성은 다음과 같다.
- 유저가 해당 채널에서 시청한 영상의 개수
- 유저가 해당 토픽의 영상을 시청한 마지막 시간
- 입력된 candidates의 출처와 score
- 시청 영상 목록 중 과거 영상의 빈도
- 유저의 Churn 여부를 확인할 수 있는 지표로 잘 활용했다고 한다.
- 연속형 변수의 경우 분포를 고려할 수 있는 CDF 값을 활용해 [0, 1)의 값으로 정규화했다.
- 앞서 얻은 변수 $x$의 $x^2, \sqrt{x}$를 추가 입력으로 사용할 경우 더 나은 성능을 기록했다.
Modeling Expected Watch Time
앞서 언급한 시청 시간을 예측하기 위해서 weighted logistic regression을 도입했다.
weight는 클릭된 경우 시청 시각을, 클릭되지 않은 경우엔 1(아마도?)을 부여한다.
학습을 통해서 odds는 $E[T](1 + P)$와 유사해지는데 P(클릭 확률) 값이 적다는 점을 고려하면, odds는 $E[T]$와 비슷해진다. 이는 곧 odds 값을 통해서 expected watch time을 얻을 수 있음을 의미한다.
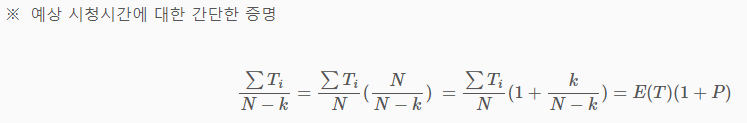
실험 결과 확인
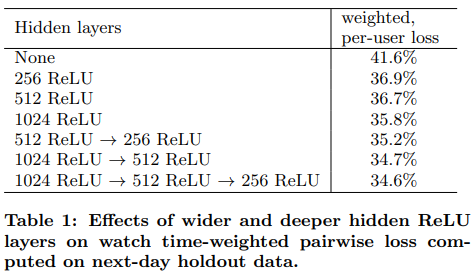
- FC의 차원을 늘릴 수록 성능이 증가했다.
- FC를 쌓을 수록 성능이 증가했다.
- 표에는 언급되지 않았지만 클릭된 경우/클릭되지 않은 경우에 따른 weight를 설정하지 않고 훈련했을 땐 loss가 4%나 증가했다고 한다.
참고
딥러닝을 이용한 자연어 처리(Natural Language Processing with Deep Learning) – CS224n 강의 노트 1-2 | 솔라리
이 글은 스탠포드 대학에서 제공하는 딥러닝을 이용한 자연어 처리(Natural Language Processing with Deep Learning)-CS224n- 강의노트(Lecture Note) 1장의 뒷 부분을 번역한 글이다. [2] 아래의 이미지는 CBOW와 Skip-
solarisailab.com
- Negative Sampling과 Hierarchical softmax의 내용을 확인할 수 있다.
[논문요약] DNN for YouTube(2016) - 추천 딥러닝 모델의 바이블
*크롬으로 보시는 걸 추천드립니다* https://static.googleusercontent.com/media/research.google.com/ko//pubs/archive/45530.pdf 종합 : ⭐⭐⭐⭐ 1. 논문 중요도 : 5 점 2. 실용성 : 4 점 설명 : 추천 시스템에 적용된 딥러
kmhana.tistory.com
- odds와 시청 시간 사이 관계를 확인하는 과정에서 참고했다.