
Concept
Ensemble(앙상블) 기법을 활용하면 모델의 성능을 향상 시킬 수 있다. 하지만 앙상블에 사용할 모델을 추가로 저장하고, 또 추론 시 불러와야 하기 때문에 실행이 오래 걸린다는 문제점이 있다. 이때, Knowledge Distiliation(KD)으로 단일 모델을 구성하면 일종의 앙상블 효과를 얻으면서, 동시에 언급한 단점들을 해결할 수 있다.
KD는 일반적으로 마지막 레이어의 소프트 라벨만 활용해서 진행된다. 하지만 MEAL은 중간 레이어의 Feature Vector 까지 유사하도록 만들기 위해, KD를 레이어 중간 마다 진행하면서 동시에 Adversarial Loss 까지 도입한다. 이를 Block 단위로 처리할 수 있도록 Adaptive Pooling을 도입했고, 이는 다양한 구조의 Teacher(T) 모델을 간단하게 통합할 수 있도록 도와준다.
MEAL은 이러한 KD 방식(중간 레이어 + Adversarial Loss 추가)으로 정확도가 향상 됐고, robust한 S 모델을 얻을 수 있게 됐다. 아마도 유사한 Feature Vector를 얻기 위한 추가 작업 때문이 아닐까 싶다.
Introduction
One-hot vector인 Hard Label을 앙상블에 사용할 경우, 각 모델들의 Information(정보)와 Knowledge(지식)가 온전히 활용할 수가 없다. 따라서 앙상블 사용에 따른 연산량 증가에 비해 얻을 수 있는 이점이 한정적이다.
하지만 모델의 예측 확률(또는 로짓)을 이용한 Soft Label을 활용하게 되면 좀 더 다양한 정보를 반영할 수 있다. 실제로 동일한 이미지더라도 모델에 따라 다른 Soft Label 분포를 가지게 되는데, 이는 모델의 정보, 지식이 Soft Label에 녹여져 있을 수 있다는 것을 의미한다.
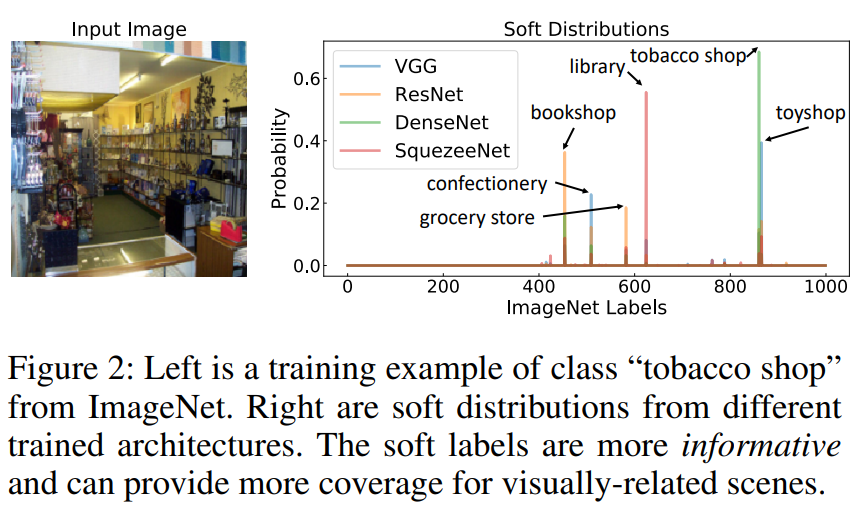
그래서 KD에선 Soft Label을 이용한 앙상블이 활용된다.
MEAL 또한 KD를 활용하기 때문에 Soft Label을 활용한다. MEAL은 추가로 robust한 S 모델을 위해 T - S에 대해 Adversarial Learning을 활용했다.
Overview
MEAL의 구조는 다음과 같다. Siamese 구조로 동일 입력을 T - S 모델에 입력하고 Block-wise Loss로 Similarity Loss와 Adversarial Loss를 계산한다.
Block-wise Loss 도입은 Intermediate Alignment 효과를 얻을 수 있도록 도와줘, 단순 예측 결과 뿐이 아닌 레이어 사이의 Feature Vector 까지 유사하도록 만든다.
이러한 Block-Wise Loss는 Adaptive pooling을 사용하기 때문에 Feature Vector의 크기가 다르더라도 활용이 가능하다. 이를 통해 Teacher/Student의 구조가 다르더라도 Block의 개수만 동일하면 MEAL을 쉽게 활용할 수 있다.
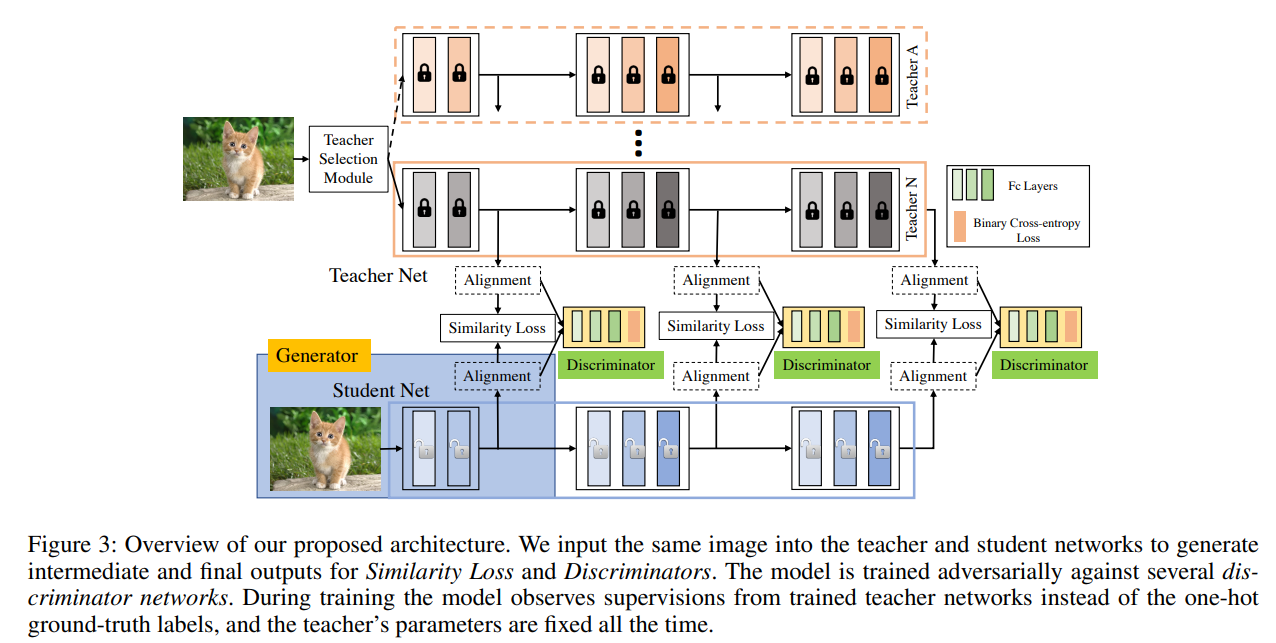
Block-wise Loss는 Simillarity Loss와 Adversarial Loss의 가중합으로 구성된다. Similarity Loss는 일반적인 KD에서 활용되는 그것과 동일하다. Adversarial Loss는 Generator(S)의 Feature Vector가 T의 것과 유사하도록 도와준다.
Similarity Measurement
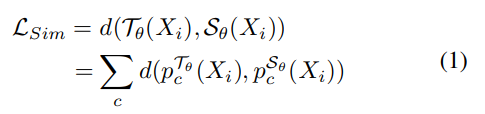
$T_{\theta}$와 $S_{\theta}$는 각각 T, S 모델이다.
주어진 $X_i$에 대해 각각 계산된 Soft Label 차이를 통해 Similarity를 얻을 수 있다.
Similarity를 계산하기 위해서 $l1, l2, KL - divergence$를 활용해볼 수 있다.
실험 결과 $KL divergenc$e가 가장 좋은 성능을 기록했다.
$KL - divergence$를 계산하는 과정에서 T 모델의 Entropy를 구하는 부분은 상수이기 때문에, Cross Entropy loss로 단순화할 수 있다. 과정은 아래와 같다.
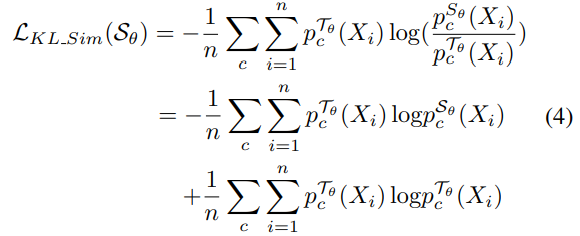
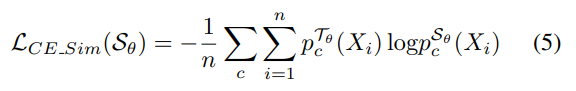
앞서 얘기했듯, MEAL에선 Similarity를 마지막 레이어에서만 구하지 않고, Block 단위로도 확인한다.
Block 단위로 처리하려면, 모델의 종류마다 그 Block에서의 Vector 크기가 다를 수 있다는 점을 고려해야 한다.
이를 위해서 MEAL에선 Adaptive padding을 활용한다.
Adaptive padding은 다양한 방법이 있지만, MEAL의 경우 Average padding을 하는 것이 가장 좋은 성능을 기록했다고 한다.
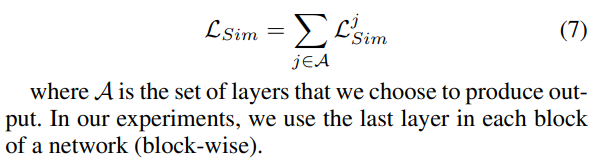
Adversarial Learning
Adversarial Learning은 S의 Feature가 T의 Feature와 유사하도록 만드는 것이 목적이다.
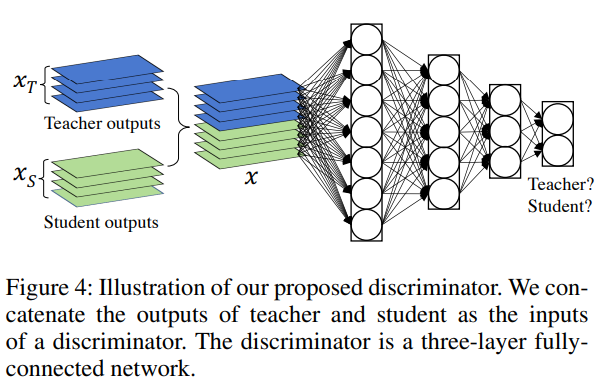
이를 위해 Feature Vector $X_{Teacher}$와 $X_{Student}$를 concat 후 MLP를 태워서 확인한다.
이 또한 Block 단위로 반복하기 때문에 최종적으로 $L_{GAN}$은 각 Block에서의 합을 통해 계산된다.
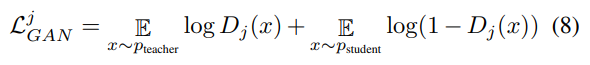
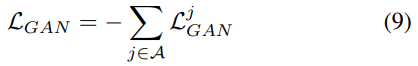
Joint Training of Similarity and Discriminators(Adversarial learning)
MEAL의 Loss는 Similarity Loss와 Adversarial Loss의 가중합으로 구성된다고 했다.
이때 각각의 가중치는 $\alpha$, $\beta$는 모두 1이다.
$L_{sim}$과 $L_{GAN}$는 Block 별로 진행된다고 했다.
이때 Block 단위로 다른 영향력을 고려하기 위해 Weighted Sum을 통해서 계산된다.
Weight 구성은 3 - Block의 경우 [0.01, 0.05, 1], 5 - Block의 경우 [0.001, 0.01, 0.05, 0.1, 1]이다.
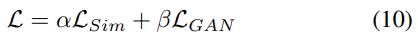
Learning Procedure
학습 과정을 pseudo code로 표현하면 다음과 같다.
매 iteration 마다 다른 T가 선택되기 때문에, 앙상블 효과를 얻을 수 있다.

Experiments
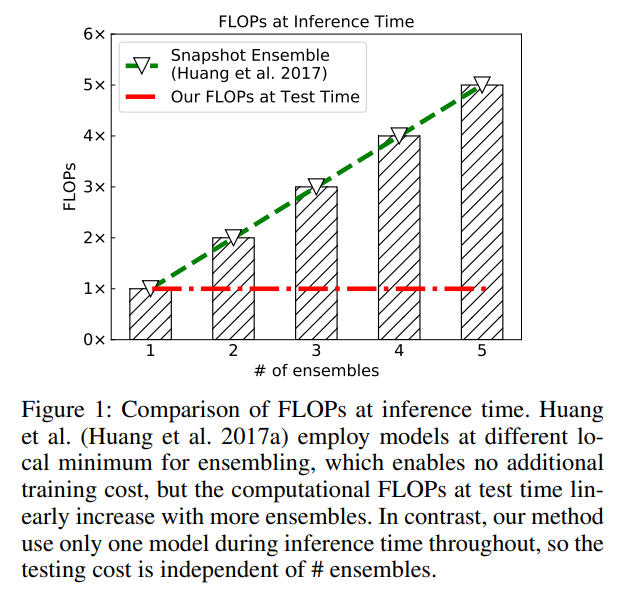
FLOPs 확인하기
MEAL의 경우 KD 기반으로 앙상블 하기 때문에 추론 때도 FLOPs가 동일하다.
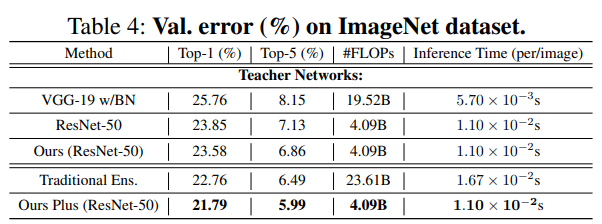
Teacher 모델 구성에 따른 성능 변화
VGG-19와 ResNet-50을 T로 ResNet-50을 S로 구성했을 때(Ours) 기존 VGG - 19, ResNet-50 대비 성능 향상이 있었다. T를 ResNet-101, 152와 같은 성능이 좋은 모델로 변경할 경우(Ours Plus) 성능 향상을 기록했다.
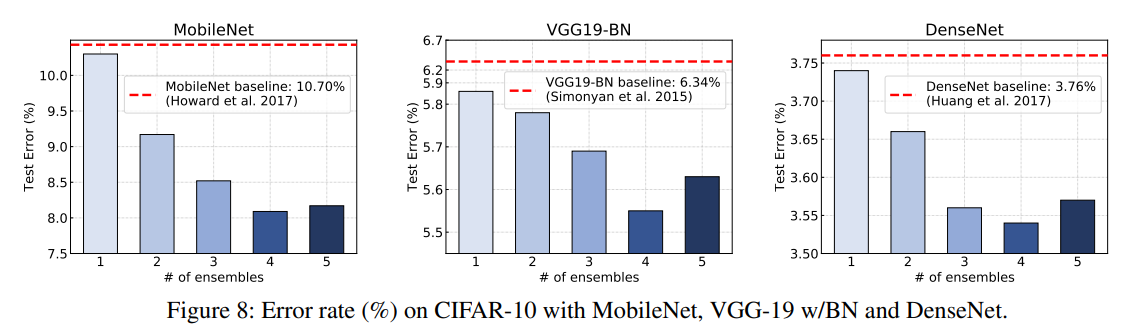
Teacher 모델의 수에 따른 성능 변화
T를 구성하는 모델의 수가 늘어날 수록 성능 향상을 기록했다. 이때, T의 수가 4보다 커지면 오히려 성능이 하락 됐다.
Feature Embedding : intermediate alignment의 효과?
MEAL을 통해 얻은 임베딩과, 일반 모델의 임베딩을 비교한 그림이다.
우측에 있는 그림이 MEAL의 그림인데 Label 분포가 좀 더 개선 됐음을 확인할 수 있다.

참고