
머신러닝 시스템 설계 : MLOps
MLOps 구성 요소
- 비즈니스 요구 사항 구현
- 데이터 스택 관리
- 인프라 구축
- 배포 및 모니터링
MLOps 구축 과정
- ‘목적’, ‘요구사항’, ‘프로세스’를 설계하고 구축해야 함
- ‘왜 필요한 지’ → ‘신뢰성, 확장성, 유지보수성, 적응성을 만족하는 지’
- 개선 작업이 반복적으로 발생함
- 풀고자 하는 문제를 ML로 해결 가능한 형태로 구조화해야 함
- 동일한 문제더라도 구조화 방식에 따라 난이도는 천차만별
2.1 비즈니스와 머신러닝의 목적
ML 프로젝트 목적 고민 필요
- ML 지표 vs 비즈니스 지표
- 연구가 아니라면 비즈니스 지표를 ML 프로젝트로 끌어올릴 방법을 찾아야 함
비즈니스의 핵심은 이익 극대화 → ML 프로젝트로 어떤 ‘성과 지표’에 영향을 줄 수 있는지 설명할 수 있어야 함
- ML 프로젝트가 비즈니스 지표에 미치는 영향을 명확히 파악하기 위해 A/B 테스트가 필요함
- 비즈니스-ML 지표 사이 연결을 위해선, 목적에 맞는 지표(새롭게 만들 수도)를 설정하는 것이 중요함
- CTR 예측, Anomaly Detection은 모델 성능과 성과 지표 사이 연결이 쉽기 때문에 많이 활용 되는 분야 임
- 새로운 지표 설정 → 넷플릭스 : 채택률(추천 썸네일 중 몇 개나 클릭했는지)
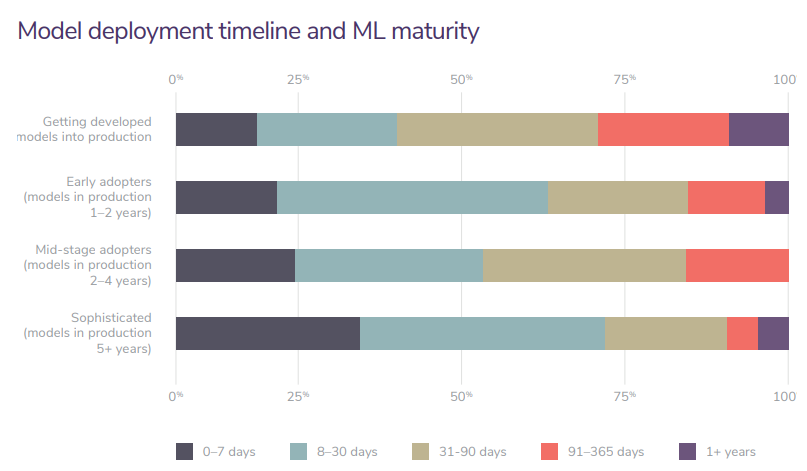
ML 시스템 도입 경험이 많을 수록 배포까지 걸리는 시간이 줄어 듦 2.2 머신러닝 시스템 요구 사항
신뢰성이 있는지
- ML 시스템은 HW/SW 결함 또는 사람에 의한 오류가 발생하더라도 목표 성능을 만족해야 함
- 제대로 된 예측을 하고 있는지 확인 필요
확장성이 있는지
- 모델의 복잡도, ML 시스템의 트래픽 양, 관리해야 하는 모델 수가 늘어날 수 있음
- 다양한 형태의 규모 증가를 처리하기 위해선 Auto-scaling(Scaling out 자동화)가 필요함
유지보수가 용이한지
- ML 시스템의 다양한 구성원(ML 엔지니어, 데브옵스 엔지니어, 도메인 전문가)과 협업할 수 있어야 함
- 코드 문서화, 코드/데이터/ML 모델 등의 버전 관리가 필요함
적응성이 높은지
- 시스템이 변화하는 데이터 분포와 비즈니스 요구 사항에 대응할 수 있어야 함
- 성능 형상에 영향을 주는 요소를 파악해야 함
- 서비스 중단 없이 업데이트가 가능하도록 구성해야 함
- 유지 보수가 용이 → 적응성이 높은 시스템과 연관
2.3 반복 프로세스
- ML 시스템 개발은 반복적이고 끝이 없는 프로세스로 구성 됨
- 시스템을 프로덕션 환경에 배포하면 지속적으로 모니터링하고 업데이트해야 함
예시 : 사용자의 검색어 입력 시, 광고 노출 여부를 판단하는 ML 모델 개발 과정
- 최적화 지표 선정 : 노출 횟수
- 데이터 수집 및 레이블링
- 피처 엔지니어링
- 모델 학습
- 오류의 원인이 되는 잘못된 레이블 수정
- 모델 재 학습
- 불균형 클래스 문제 확인 → 노출 광고에 대해서 더 많은 데이터 수집 필요
- 모델 재 학습
- 최근 데이터에 대해선 성능이 좋지 않음을 확인 → 데이터를 최신으로 업데이트
- 모델 재 학습
- 모델 배포
- 광고 노출과 수익이 관련 없음을 확인 → 최적화 지표를 클릭률로 변경
- 2 부터 다시 시작!
반복 프로세스 단계 별 요구 사항
1 단계 : 프로젝트 범위 산정
- 프로젝트 적용 범위를 설정하고, 목표(목적) 및 제약 사항을 점검 함
- 다양한 이해 관계자와 함께 ML 프로젝트로 집중할 부분, 해결할 비즈니스 지표 등을 설정 해야 함
2 단계 : 데이터 엔지니어링 진행
- 모델이 학습할 데이터를 관리 및 처리하는 방법을 점검 함
3 단계 : ML 모델 개발
- 데이터셋으로 Feature를 추출하여 초기 모델을 구성함
4 단계 : 모델 배포
- 개발한 모델에 사용자가 접근할 수 있도록 설정함
- 모델이 어느 정도 완성된 시점(완벽하지 않아도 됨!)에 진행
5 단계 : 모니터링과 연속 학습
- 모델의 성능 저하를 모니터링하고, 변화하는 환경 및 요구 사항에 적응할 수 있도록 유지 관리 함
6 단계 : 결과를 비즈니스 관점에서 분석
- 모델 성능을 비즈니스 목표 관점에서 평가, 분석해 인사이트를 추출함
- 인사이트를 바탕으로 비생산적인 프로젝트를 중단하거나 새로운 프로젝트의 범위를 산정
2.4 머신러닝 문제 구조화하기
예시 : ML을 사용해 고객 요청 처리 속도를 빠르게 만들자.
- 고객 요청 처리 속도 향상 → ML로 직접적으로 해결할 수 있는 문제가 아님
- ML로 해결 가능한 형태로 문제 재정의 필요
- 만약 고객 요청을 분류하는데 시간이 오래 걸린다면, ML을 사용해 분류 문제를 해결하면 됨
2.4.1 머신러닝 작업 유형 결정하기
다중 클래스 분류
- 대략적으로 클래스당 최소 100개 이상의 데이터가 있어야 분류할 수 있음
- 클래스가 많은 경우 계층적 분류(상위-하위 카테고리 각각 분류)도 고려 가능
다중 클래스 vs 다중 레이블 분류
- 데이터가 여러 클래스에 동시에 속할 수 있으면 다중 레이블 분류 문제임
- 다중 레이블 분류 문제 해결 방법
- 다중 클래스 분류랑 동일하게 처리 → 데이터 형태 : [0, 1, 0, 0], [0, 1, 0, 1]
- 다중 이진 분류 형태로 풀기 → 풀이 형태 : [0/1] [0/1] [0/1] [0/1]
다중 레이블 분류의 어려움
- 데이터마다 속하는 클래스 수가 다름
- 확률(Softmax 함수 결과)로부터 예측 결과를 도출하기 어려움
- 레이블링 자체도 어려움
문제 구조화 과정 → 예시로 이해하기
예시 : 스마트폰 사용자가 다음으로 사용할 앱 예측
- 다중 클래스 분류 문제
- 이전 이용 정보, 사용자 정보 등을 활용해 모든 앱(N 개)에 대한 클릭 확률 예측
- N이 변할 경우(신규 앱 출시) 새로운 학습 필요하다는 단점

- 회귀 문제
- 앱을 클래스로 다루지 않고, 앱 관련 Feature를 추가로 입력해 클릭 확률을 예측
- N에 의존적인 대신, 각 예측을 N 번 수행하면 됨
- Feature로 표현할 수 있다면, 신규 앱도 추천할 수 있음

2.4.2 목적 함수 결정하기
- 목적 함수를 사용해 ML 시스템의 성능을 정량화 해야 함
- 해결할 문제가 여러 개일 경우 2 가지 접근법 존재
- 여러 개의 목적 함수를 가중치를 사용해 1 개로 통합
$$
loss = \alpha(loss_1) + \beta(loss_2)
$$
- $\alpha$와 $\beta$를 조정할 때 마다 모델을 새롭게 학습해야 함
- 두 모델의 출력을 결합하고, 결합한 점수로 게시물 순위를 지정함
$$
score = \alpha(loss_1) + \beta(loss_2)
$$
- $\alpha$와 $\beta$를 조정하더라도 모델을 새롭게 학습할 필요가 없음
- 유지 보수가 쉽기 때문에 추천하는 방법
- 모델 마다 학습 주기가 다를 경우 더욱 더 유용함
2.5 지성(Bias, Architecture) vs 데이터(+Cost)
지난 10년 간의 발전 과정
- ML 시스템의 성공 여부 → 주로 학습 데이터가 판가름
- 기업들 대부분은 ML 알고리즘 개선보다는 데이터 관리와 개선에 집중
앞으로의 발전 전망
| 지성 중심 | 온건파 | 데이터 중심 |
|---|---|---|
| 데이터 중심의 ML 분야 종사자는 3 ~ 5년 안에 일자리를 잃을 것 | 단순 데이터 투입으론 성능 향상 한계. 더 적은 데이터로도 의미 있는 모델이 필요 함 | 순간의 혁신 말고, 장기적 개선은 항상 대량의 데이터가 필요 했음 → 앞으로도 그럴 것 |
| - 데이터가 성공의 필요 조건임은 확실함 | ||
| - 모든 의사 결정의 기초가 되기 때문 |
2.6 정리
- ML 프로젝트 시행 전 항상 ‘왜? 필요한지’ 고민하는 것이 필요함
- ML 지표 보단 비즈니스 성과가 중요 → ML 모델이 비즈니스 목표를 이룰 수 있어야 함
- ML 프로젝트를 성공시키기 위해선 좋은 시스템이 필요함
- 일반적으로 신뢰성, 확장성, 유지보수성, 적응성이 높다면 좋은 시스템이 될 수 있음
- ML에서 데이터가 전부는 아니지만, 또 데이터만큼 중요한 것도 없다!