
Classification Metrics(분류 모델 평가 지표) 알아보기 : Accuracy, Precision, Recall, F1 Score
Intro
여러 분류 모델 중 해결해야 하는 문제의 특성, 데이터 등 다양한 사항을 고려해 몇 개의 모델을 추리는데 성공했다고 가정해봅시다. 이때 가장 성능이 좋은 모델을 선택하기 위해선 얼마나 정확하게 주어진 문제를 해결할 수 있는 지를 수치화하여 비교하는 것이 중요합니다.
모델 평가를 위해 정확성을 수치화하여 나타낸 것을 평가 지표라고 하며, 적절한 평가 지표를 설정하는 것은 매우 중요한 작업입니다. 이번 포스팅에선 기본적인 평가 지표인 Accuracy, Precision, Recall에 대해서 다뤄보겠습니다.
Confusion Matrix(혼동 행렬)

분류를 성공적으로 했는지를 확인하기 위해서는 혼동 행렬을 살펴볼 필요가 있습니다.
혼동 행렬이라는 이름처럼 처음에 접했을 때는 매우 헷갈립니다. TP, FN, FP, TN 이 각각 무엇을 뜻하지는지 직관적으로 와 닿지가 않습니다.
True/False와 Positive/Negative가 각각 쌍이라고 생각하면 이해하기 쉽습니다. True/False는 예측의 성공과 실패 여부를 알려주고 Positive/Negative는 어떻게 예측했었는지를 보여줍니다. 풀어쓰면 다음과 같습니다.
- TP : Positive로 예측했는데 실제도 Positive라서 예측이 True
- FN : Negative로 예측했는데 실제는 Positive라서 예측이 False
- FP : Positive로 예측했는데 실제는 Negative라서 예측이 False
- TN : Negative로 예측했는데 실제도 Positive라서 예측이 True
이제 혼동 행렬을 확인했으니 평가 지표들을 확인해보도록 하겠습니다.
Accuracy(정확도)
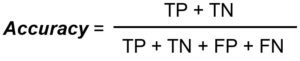
일반적으로 많이 사용되는 평가 지표입니다. 전체 분류 문제 중(Total) 얼마나 정답을 맞췄는지(TP + TN)에 대한 비율입니다.
겉보기에는 문제가 없어보이는 평가 지표이지만 데이터의 불균형이 심할 경우엔 문제가 생기게 됩니다. 조금 극단적인 예시를 들어 설명해보겠습니다.
목표 : 99개의 Positive 샘플과 1개의 Negative 샘플을 가장 높은 정확도로 분류하는 모델을 만들자!
이 경우 아무런 기준 없이 모든 샘플을 Positive로만 예측하여도 정확도는 99%라는 높은 수치를 가지게 됩니다.
정확도를 평가 기준으로 삼으면 어떠한 작업도 하지 않고 모든 것을 Positive로 처리하는 것이 가장 최선이게 됩니다. 이는 원하는 결과가 아닙니다.
불균형한 데이터가 Fraud Detection, Diagnosis와 같은 곳에서 활용되는 것을 생각해보면 더욱 그렇습니다. 이런 상황을 피하기 위해선 정확도를 평가 지표로 사용하기 전 데이터의 불균형을 반드시 확인해야 합니다.

Precision(정밀도)

정밀도는 전체 Positive 예측(TP + FP) 중 얼마나 정답(TP)을 맞췄는지를 알려주는 수치입니다.
정밀도는 보통 재현율과 함께 언급됩니다.
정밀도와 재현율 모두 TP를 분자로 설정해 전체 중 TP의 비율의 중요성을 보여주는 지표입니다.
이때 기준이 되는 전체 경우의 수를 어떻게 설정하는 지에 따라서 정밀도와 재현율로 구분됩니다.
Recall(재현율)
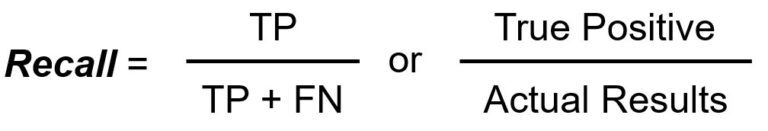
재현율은 전체 Positive 경우(TP + FN)중 얼마나 정답(TP)를 검출했는지를 알려주는 수치입니다.
정밀도와 재현율은 각각 FP와 FN을 고려합니다. FP와 FN을 고려한다는 것은 풀어쓰면 다음과 같습니다.
FP 고려 : 표본에 대한 Positive 예측이 얼마나 정확한지를 생각한다.
FN 고려 : Positive 표본을 얼마나 잘 검출했는지를 생각한다.
이처럼 정밀도와 재현율의 의미를 정확히 파악한 뒤 사용하는 것이 중요합니다.
만약 코로나 확진자를 분류할 때는 정밀도와 재현율 중 무엇이 더 중요할까요? 이 경우엔 확진자를 놓치지 않는 것이 중요하기 때문에 재현율이 더 중요할 것입니다.
F1 Score
정밀도와 재현율 중 하나를 선택할 수도 있지만 정밀도와 재현율을 통합해서 사용하는 방법(F1 Score)도 있습니다.
정밀도와 재현율 모두를 고려하기 때문에, 불균형한 데이터에서도 활용할 수 있는 지표 입니다.

Recall vs Precision → Trade-Off
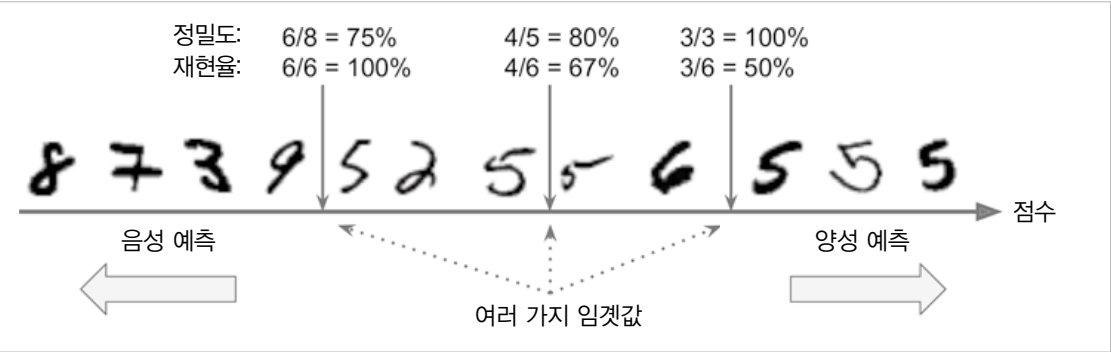
정밀도와 재현율은 Trade-Off 경향성이 있습니다. 숫자 5를 판별하는 분류기의 임곗값을 키우고 줄여보면 그림과 같은 결과를 얻을 수 있습니다.
양성 예측의 임곗값을 높이게 되면 Positive 판단에 엄격해져 정밀도가 높아지게 되지만 동시에 재현율은 감소하는 경향이 있습니다. 반대로 임곗값을을 낮추게 되면 상대적으로 후한 판단에 정밀도는 낮아지게 되고 재현율은 증가하는 경향이 있습니다.
참고
데이터 과학자와 데이터 엔지니어를 위한 인터뷰
핸즈온 머신러닝
https://machinelearningmastery.com/failure-of-accuracy-for-imbalanced-class-distributions/