
Full Stack Deep Learning - Lecture 1: Course Vision and When to Use ML
Introduction to planning, developing, and shipping ML-powered products.
fullstackdeeplearning.com
모든 사진과 글은 위 링크를 참고했습니다.
ML은 언제 활용해야 할까
머신러닝 프로젝트는 연구적 성향이 강하기 때문에 다른 소프트웨어 프로젝트와 비교 했을 때 실패 확률이 높다. 또한 많은 양의 데이터를 처리하기 위해 시스템이 복잡해져 유지 보수 과정에 큰 비용이 든다. 따라서 머신 러닝을 프로젝트에 도입하기 전엔, 다음과 같은 사항을 고려해 정말 필요한 지 따져 보고 도입하는 것이 중요하다.
- 정말 사용할 준비가 됐는지? : 데이터를 적절하게 수집하고 있는 프로덕트가 있는지, 기술적 인력이 있는지
- 정말 머신 러닝을 활용해서 문제를 풀어야 하는지? : 간단한 통계, 룰 기반으로도 해결되는 문제가 아닌지
- 해당 문제를 머신 러닝으로 푸는 것이 윤리적인지?
중요 고려 사항 : Impact - Feasibility 측면
프로젝트에 머신러닝을 도입하기로 했다면, 어떤 문제를 머신러닝으로 풀 지 우선 순위를 정하는 것이 중요하다. 우선 순위는 Impact와 Feasibility 측면에서 고려할 수 있다. 각각의 경우 고려 사항은 다음과 같다.
- Impact
- 머신 러닝을 적용해 문제를 해결 했을 때, 경제적 이득이 있는지
- 프로덕트에 필요한 것이 무엇인지
- 복잡하고, 반복적인 작업을 대신하는 것인지
- 산업에서 적용되고 있는지

- Feasibility
- 데이터를 쉽게 얻을 수 있는지, 라벨링 비용이 어느 정도인지, 데이터가 얼마나 필요한지, 데이터가 신뢰할 만한지
- 예측 정확도가 얼마나 중요한지(경제적, 윤리적), 예측 주기가 어느 정도인지
- 문제가 잘 정의돼 유사 성공 사례를 참고할 수 있는지, 컴퓨팅 성능이 충분한지, 사람이 해결 가능한 문제인지
ML에서 어려운 문제는 무엇인가

- 예측 결과가 고차원 구조이거나, 정답이 모호한 문제
- 대화 시스템, 오픈 도메인 추천 시스템의 경우 확실한 오답은 있을 수 있지만, 정답의 경우 기준이 모호함
- 분포가 다른 데이터에서 에러를 최소화하고, Adversarial attack에도 대응할 수 있도록 높은 신뢰도가 요구되는 문제
- 새로운 데이터에 대해서 잘 동작할 만큼 높은 일반화 성능을 요구하는 문제
ML 프로덕트의 유형
머신 러닝 프로덕트는 크게 3가지 유형으로 나눌 수 있고, 각 유형 마다 일반적으로 중요하게 고려하는 사항이 있다.
프로젝트 계획을 세울 때 참고하여 성공 확률을 높일 수 있다.

- Software 2.0(자동화 확대) : 새롭게 구성한 모델이 정말 효과적인지, Data Flywheel에 따라 성능이 더 증가될 여지가 있는지
Data Flywheel이란 모델 개선 ↔ 사용자 증가 ↔ 데이터 증가 의 선순환을 의미한다.
실현을 위해선 3가지 조건이 충족돼야 한다.
- 사용자들에게 라벨링된 데이터를 얻을 수 있는 Data Loop가 존재하는지, Data Loop로 얻는 데이터의 품질을 개선시킬 수 있는지
- 더 많은 데이터가 더 좋은 모델로 이어질 수 있는지
- 모델 개선이 사용자 증가로 이어질 수 있는지
- Human-in-the-loop : 사람 입장에서 필요한 게 무엇이고, 효과가 있을지
- 자율 시스템 : 실패할 확률이 어느 정도 되고 실패에 따른 결과가 어떻게 될 것인지
프로덕트 유형 별 특성 : Impact - Feasibility 측면
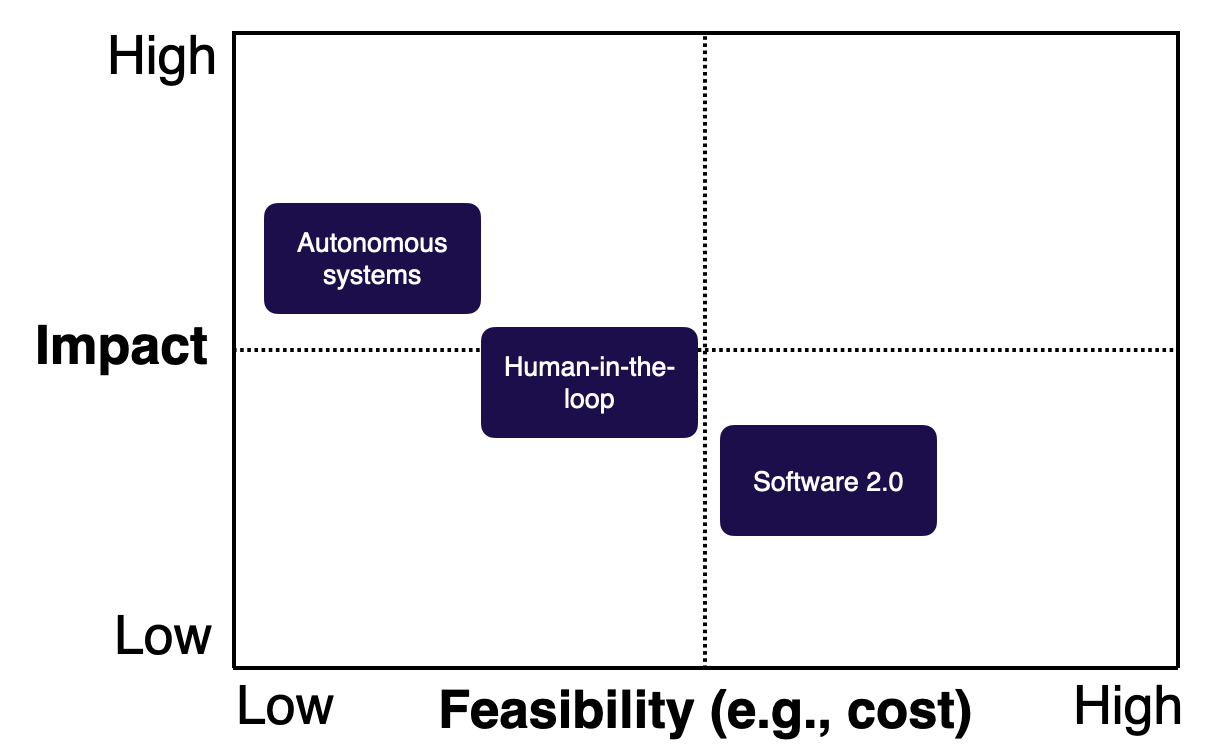
프로덕트 유형 별 Impact - Feasibility를 대략적으로 나타내면 위 표와 같다. 참고하여 프로젝트의 상황을 대략적으로 점검하고 개선 방향을 설정할 수 있다.
예를 들면, Software 2.0 의 경우 Data Flywheel을 통해 이용자를 효과적으로 늘린다면 Impact를 키울 수 늘릴 수 있을 것이다. Human-in-the-loop에서 Feasibility를 늘리고 싶다면 디자인을 변경하는 것이 좋은 방법일 수 있다. 좋은 디자인은 비교적 낮은 성능(저비용)에도 고객이 만족할 수 있게 하기 때문이다. Autonomous system에선 Feasibility를 늘리기 위해 가드레일을 설치해 사고 발생 시 위험을 줄일 수 있다.
ML 프로젝트 Lifecycle → MLOps의 도입


머신러닝 기반 프로젝트의 life cycle을 표현하면 왼쪽 그림과 같다. 복잡한 화살표를 보면 알 수 있겠지만, 각 단계에서 피드백을 얻고 개선에 활용하는 작업이 끊임없이 이뤄진다. 이러한 과정에서 필요한 기술 스택과 적용 방법들이 표준화되면서 모델을 어떻게 편하게 관리하고 개선할 지 고민하는 MLOps가 등장했다.


MLOps의 핵심은 결국 머신 러닝이 빠르게 실제 프로덕트와 서비스에 적용될 수 있도록 돕는 것이다. 실제로 연구 환경(Flat-Earth)과 다르게 프로덕트/서비스 환경에선 일련의 과정(데이터 수집 - 모델링 - 모니터링 등)을 끊임 없이 반복해야 한다. 따라서 이러한 과정을 효율적으로 관리하는 MLOps가 중요하고 또 필요하다.