
Testing(테스트)이 무엇이고 왜 필요한가요?
코드에 버그가 있는지 확인하는 작업을 Testing(테스트)라고 한다. 테스트는 코드가 가지고 있는 문제점을 프로젝트에 적용하기 전에 미리 확인할 수 있다는 점에서, 프로젝트 유지 보수에 큰 도움이 된다.
따라서 테스트를 잘하는 것은 프로젝트 성공에 매우 중요한 요소 중 하나이다.
성공적인 테스트를 위해선 우선 테스트 통과 여부와 버그 발생 여부가 항상 100% 관련 있지 않다는 점을 알아야 한다. 실제로 테스트를 통해서 확인할 수 있는 것은 단순히 '정해둔 테스트 케이스 조건을 지켰는지'이다. 결국 테스트의 효과를 극대화하기 위해선 테스트 케이스를 잘 설정하는 것이 중요하다.
그럼 어떻게 테스트 케이스가 설정 됐을 때 '잘' 됐다고 말할 수 있을까?
답을 하기 위해선 우선, 테스트 케이스 설정의 본질이 규칙을 만들고 관리하는 것이라는 점을 알아야 한다. 실제로 규칙을 추가하면 관리할 수 있는 버그 수를 늘릴 수 있지만, 동시에 규칙 때문에 잘못된 알림이 증가할 수 도 있다.

따라서 효과적인 테스트를 위해선, 테스트 케이스의 개수가 늘어나면서 효용이 오히려 감소할 수 있다는 점을 주의하고, 정말 필요한 테스트 케이스만 설정하고 관리하는 것이 필요하다.
테스트 케이스를 설정할 땐 우선, 테스트를 통해 어떤 문제(효과)를 해결할 수 있고 또 어떤 오류(부작용)를 발생 시키는지 확인하는 것이 필요하다. 이를 위해서는 진행 중인 프로젝트의 특성을 고려해야 한다. 프로젝트의 특성마다 효과와 부작용의 가치가 다를 수 있기 때문이다.

실제로 일반적인 프로젝트에선 테스트 케이스 설정으로 인한 효과는 버그 방지이고, 부작용은 잘못된 버그 판단 증가일 것이다. 이 경우엔 효과와 부작용을 따져본 뒤 만약 부작용이 더 크다면 해당 케이스는 추가하지 않는 것이 좋을 것이다.
하지만 정확도가 매우 중요한 분야(자율 주행, 의료 진단 등)의 프로젝트라면 테스트 케이스로 인한 효과는 인명 피해 방지이고, 부작용은 잘못된 버그 판단 증가일 것이다. 이처럼 부작용이 효과에 비해 굉장히 사소한 경우엔 웬만해선 테스트 케이스를 추가하는 것이 좋을 것이다.
추가로 프로젝트 특성과 상관 없이 테스트 케이스가 중요한 역할을 하는 영역이 있다. 바로 에러 처리 코드 부분이다. 이는 저자가 다양한 에러를 분석하여 얻은 결론이라고 하니 테스트 케이스 설정 시엔 이러한 에러 처리 영역을 우선적으로 검토하는 것이 좋을 것 같다.
# 에러 처리 코드 예시
import logging
logging.basicConfig(level=logging.WARNING)
def check_and_warn(logger, attribute, feature):
if not hasattr(logger, attribute):
warn_no_attribute(feature, attribute)
return True
def warn_no_attribute(blocked_feature, missing_attribute):
logging.warning(f"Unable to log {blocked_feature}: logger does not have attribute {missing_attribute}.")실제로 위와 같은 에러 처리 코드가 있다고 가정하고, 테스트 케이스의 필요성에 대해서 생각해보자.
위 코드는 입력 받은 인자(기능)을 logger가 지원하는지 확인하는 역할을 하는 코드다. 위 코드가 있다면 지원하지 않는 인자로 인한 에러를 사전에 차단할 수 있게 된다. 따라서 위 코드에 대해서 테스트 케이스를 적용하고 관리한다면 프로젝트의 버그를 최소화할 수 있을 것이다.
위와 같은 코드의 테스트 케이스는 사용할 logger의 인자를 임의로 제공하는 방식을 통해서 설정할 수 있다. 실제로 아래의 예시에선 TensorBoardlogger에 log_table라는 인자가 있는지 확인하는 방식으로 테스트 코드를 작성했다.
def test_check_and_warn_tblogger():
"""Test that we return a truthy value when trying to log tables with TensorBoard.
We added check_and_warn in order to prevent a crash if this happens.
"""
tblogger = pl.loggers.TensorBoardLogger(save_dir=tempfile.TemporaryDirectory())
assert not check_and_warn(tblogger, "log_table", "tables")테스트 코드에 대한 실행 결과를 살펴보면 우선, 현재 TensorBoard엔 log_table 인자가 존재하기 때문에 check_and_warn의 return 값은 None이 될 것이다.
그 결과 assert 문엔 not None이 입력되기 때문에 아무 에러도 발생 시키지 않을 것이다. 만약 이러한 테스트의 실행 결과가 예상과 다르다면 코드에 버그가 있는 것이고 수정이 필요할 것이다.
머신러닝 코드 테스트하기
머신러닝 프로젝트엔 파이썬으로 작성된 코드가 많다. 따라서 파이썬에서 사용되는 코드 테스트 툴을 활용한다.
그 중에서 많이 사용되는 테스트 툴은 Pytest와 doctest이다.
Pytest는 코드가 미리 설정해둔 테스트 케이스를 통과할 수 있는지 확인하기 위해 활용되고, doctest는 독스트링의 입력한 예제 문구가 올바르게 실행되는지 확인하기 위해서 활용된다.
이러한 pytest와 doctest는 각각 개별적으로 사용할 수 있는 툴이지만, pytest를 실행할 때 --doctest-modules 인자를 전달하면 pytest와 doctest를 동시에 활용할 수 있다.
# pytest와 doctests를 동시에 사용하기
pytest --doctest-modules 점검할 파일.py
doctest
doctest는 작성된 독스트링의 예제 코드가 정확한지 확인하기 위해 사용되는 테스트 도구이다.
독스트링은 함수, 모듈, Class, method 등에 대한 설명을 담은 문자열로, 해당 코드의 역할 및 실행 시 필요한 인자 등의 정보를 담고 있다. 추가로 정보를 효과적으로 전달하기 위해서 예제 코드가 포함되곤 한다.
정확한 예제 코드는 실행에 필요한 조건과 결과를 한 눈에 확인할 수 있다는 장점이 있지만, 잘못된 예제 코드는 엄청난 삽질을 유발할 수 있다. 따라서 작성한 예제 코드가 정상적으로 동작하는지 확인하는 것이 매우 중요하며 이것이 바로 doctest가 필요한 이유다.
참고로 독스트링에 예제 코드를 적고 싶다면 >>>에 예제 실행에 필요한 입력을 적고, 그 아래엔 출력 결과를 적으면 된다.
Examples
--------
>>> first_appearance(torch.tensor([[1, 2, 3], [2, 3, 3], [1, 1, 1], [3, 1, 1]]), 3) # 예제의 입력
tensor([2, 1, 3, 0]) # 예제의 출력
>>> first_appearance(torch.tensor([1, 2, 3]), 1, dim=0)
tensor(0)doctest을 사용해 예제 코드를 테스트하는 방법은 매우 쉽다.
확인하고 싶은 파일에서 doctest 모듈을 불러오고 testmod()를 설정한 뒤에 실행하면 끝이다.
테스트를 통과하면 아무 메시지도 나오지 않고, 실패하면 관련된 메시지가 출력된다.
# 확인할 파일에서 doctest.testmod() 설정
import doctest
if __name__ == '__main__':
doctest.testmod()
# doctest!
python 확인할 파일.py- 에러 발생 시엔 다음과 같은 메시지가 출력된다.
c:\projects\pylib>python doctest_sample.py
**********************************************************************
File "c:\projects\pylib\doctest_sample.py", line 10, in __main__.leap_year
Failed example:
leap_year(700)
Expected:
True
Got:
False
**********************************************************************
1 items had failures:
1 of 4 in __main__.leap_year
***Test Failed*** 1 failures.
출처 : https://wikidocs.net/132772Pytest
머신러닝 프로젝트의 코드 대부분은 Python으로 작성돼 있기 때문에 pytest를 활용해서 테스트를 진행한다.
pytest는 독스트링만 테스트하는 doctest와는 다르게, 프로젝트 코드 전체를 테스트할 수 있다.
Pytest로 확인하고 싶은 테스트 케이스를 설정하려면 Class의 이름 앞에 Test를 붙이거나 함수의 이름 앞에 test_ 를 붙여야 한다. 이후 확인하고 싶은 파일명과 pytest를 함께 입력하여 테스트를 진행할 수 있다.
예시로 text_recognizer/lit_models/metrics.py라는 파일을 테스트하는 상황을 가정해 보자. 아래 코드는 해당 파일의 Namespace에 있는 모든 객체의 이름을 출력한 것인데, test_로 시작하는 함수는 test_character_error_rate 뿐인 것을 확인할 수 있다. 이는 metrics 파일에서 테스트가 이뤄질 함수는 1개뿐이라는 것을 의미한다.
from text_recognizer import lit_models
dir(lit_models.metrics)
# 출력
['CharacterErrorRate',
'Sequence',
...
'test_character_error_rate', # 이 함수만 pytest가 확인
'torch',
'torchmetrics']앞서 확인한 metrics 파일을 pytest로 테스트한 결과는 아래에서 확인할 수 있다. 앞서 metrics 파일만 테스트하기로 설정했기 때문에 collected 1 item이라는 문구가 나왔고, 마지막에는 1 passed라는 문구를 통해 테스트가 성공한 것을 확인할 수 있다.
pytest text_recognizer/lit_models/metrics.py
# 결과
============================= test session starts ==============================
platform linux -- Python 3.8.10, pytest-7.1.1, pluggy-1.0.0
rootdir: /content/fsdl-text-recognizer-2022-labs, configfile: pyproject.toml
collected 1 item
text_recognizer/lit_models/metrics.py . [100%]
============================== 1 passed in 5.97s ===============================앞서 pytest는 Class와 함수의 이름 앞에 붙은 표식(Test, test_)을 통해 테스트를 진행한다고 했었다. 추가로 pytest는 이름에 test_*.py 또는 *_test가 붙은 파일 또한 확인할 수 있다.
따라서 예시처럼 기존의 파일을 유지한 상태에서 테스트할 함수와 Class의 이름만 변경해도 되지만, 별도의 파일을 새롭게 생성하여 테스트 코드를 관리할 수 있다.
테스트 코드를 별도의 파일로 관리하게 되면, 여러 곳에 분산 시킬 때 보다 코드를 효과적으로 관리할 수 있다.
따라서 테스트에 사용할 폴더를 만들고, 폴더를 통해 관련된 테스트 코드를 관리하는 것도 좋은 방법이다.
Code coverage란?
code coverage(코드 커버리지)란 전체 프로젝트의 코드 중 얼마나 많은 코드를 테스트 하고 있는 지 알려주는 수치이며, 테스트의 현황을 파악하고 점검하기 위해 활용된다.
이러한 코드 커버리지는 pytest-cov라는 플러그인만 추가로 설치하면 pytest를 통해서도 확인할 수 있다. 설치, 사용 방법은 블로그나 공식 문서 등에 설명이 잘 돼 있으니 참고하면 된다.
아래 코드는 pytest-cov 플러그인을 통해 커버리지를 확인한 결과인데, 여기선 전체 프로젝트 중에 metrics.py 파일 1 곳에만 테스트가 진행돼 Coverage 수치가 4 % 정도로 나왔다.
pytest text_recognizer/lit_models/metrics.py
# 결과
...
---------- coverage: platform linux, python 3.8.10-final-0 -----------
Name Stmts Miss Branch BrPart Cover
----------------------------------------------------------------------------------
text_recognizer/__init__.py 0 0 0 0 100%
...
text_recognizer/lit_models/metrics.py 19 1 8 1 93%
...
training/util.py 15 15 0 0 0%
----------------------------------------------------------------------------------
TOTAL 1714 1651 376 1 4%
...테스트 커버리지를 효과적으로 활용하기 위해선, 커버리지 수치에 집착하지 않는 것이 중요하다.
이는 커버리지 수치 자체가 테스트 품질과 100 % 관련 있다고 보기 어렵기 때문이다.
실제로 아무 의미 없는 테스트 케이스여도 모든 코드에 추가되기만 하면 커버리지 수치는 100 %가 나올 수 있다.
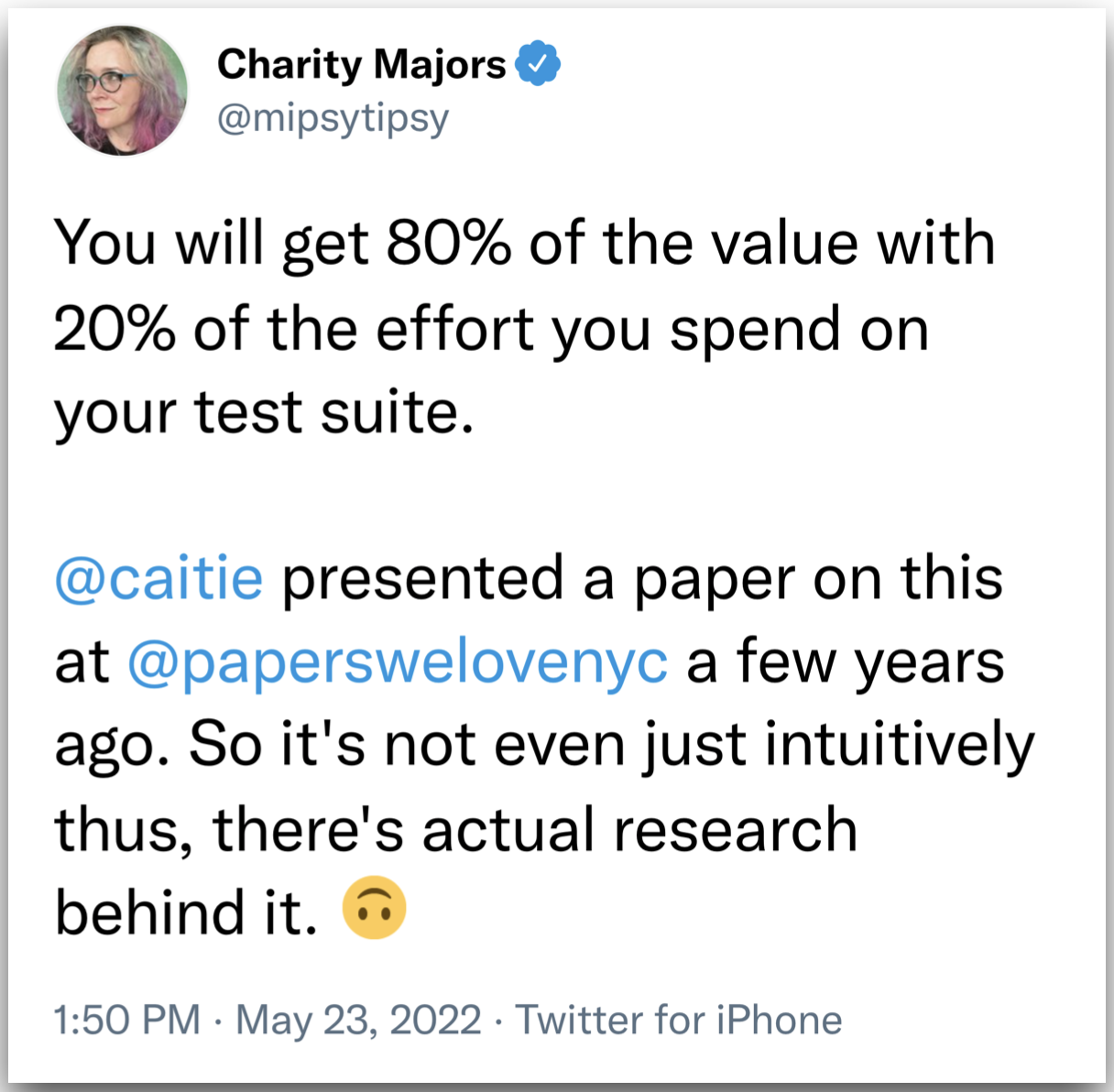
테스트 커버리지를 효과적으로 활용하기 위해선 우선은, 소수의 중요한 테스트 케이스 부터 처리하는 것이 필요하다. 따라서 테스트 초기엔 커버리지 보다는 테스트의 질을 높이는데 집중하자.
중요 케이스의 테스트 품질이 어느 정도 보장된 이후엔 커버리지를 참고해 부족한 점을 점검하자.
여러 케이스를 한번에 완벽하게 관리하기보다는, 차례로 발전시키는 것이 효과적으로 테스트를 하는 지름길이다.
코드 커버리지에 대한 자세한 설명은 더보기 탭 내 링크에서 확인할 수 있다.