
NLU와 QA에 대해서 다뤄보았으니 이번 포스팅에선 NLG(Natural Language Generation)의 전반적인 내용과 Extractive Summarization에 대해서 다뤄보겠습니다.

NLG?
NLG란 자연어 문장을 생성하는 기술입니다. 문장을 생성하기 위해서 주어진 정보(Text, Image, Video 등)을 이용합니다. 생성된 문장을 통해 주어진 정보를 축약하거나 보강할 수 있습니다. 또한 정보를 재구성하는 데도 도움을 줍니다. 이때 문장을 생성한다는 것은 결국 sequence $x$를 가장 잘 표현할 수 있는 token sequences를 얻는 것과 동일합니다.

NLG Task는 크게 보면 문장 축약, 보강, 재구성으로 구성됩니다. 간단하게 살펴보면 다음과 같습니다.
문장 축약
1. Summarization
- Abstractive / Extractive로 구분
- Abstractive : 입력 텍스트를 이해하여 새로운 문장으로 요약 생성
- Extractive : 주어진 텍스트에서 중요한 부분을 찾아내 요약 생성
- 뉴스 요약에 활용
2. Question Answering
- QA 데이터 Augmentation에 활용
3. Distractor Generation
- 오지선다에서 오답을 생성
- 데이터 Augmentation에 활용
문장 보강
1. Short Text Expansion
- 정보를 추가해 데이터의 길이를 늘리는데 활용
- 짧은 제목으로도 내용 생성 가능
2. Topic-to-essay
문장 재구성
1. Style Transfer
- 데이터 Augmentation, 말투 변형(사투리 통역)에서 활용
2. Dialogue Generation
- 챗봇에서 활용
NLG Benchmark : GEM

다양한 NLG의 Task는 각각 다른 데이터셋으로 평가됩니다.
전이 학습의 등장으로 NLU에서 종합적인 성능을 확인하기 위해서 GLUE Benchmark가 도입됐지만 NLG에선 Benchmark가 마땅히 없었습니다. 하지만 NLG에서도 최근 GEM이라는 Benchmark가 새로 도입됐습니다. 따라서 앞으로 활발한 연구가 진행될 전망입니다. GEM이 포함하고 있는 데이터셋은 위 그림을 참고해주세요.
Extractive Summarization(추출적 요약)

추출적 요약은 그림에서처럼 텍스트에서 중요하다고 판단되는 부분을 찾아내 요약문을 생성합니다. 요약문을 생성할 때 텍스트의 일부를 그대로 사용하기 때문에 요약이 매끄러울 지 않을 수 있다는 단점이 존재합니다. 추출적 요약은 크게 3가지 단계로 진행됩니다. 딥러닝 모델 이외에도 Graph, ML 등 여러가지 방법들이 활용될 수 있습니다. 자세한 내용은 이곳을 참고하면 좋습니다.
- 입력 텍스트를 Representation으로 변환
- 생성된 Representation을 기반으로 문장 별로 중요도 Score 평가하기
- Score를 기준으로 문장을 결합(Top - K)해서 요약문 생성하기

추출적 요약의 성능을 확인하기 위해서는 CNN_Daily Mail 데이터셋이 활용됩니다. 데이터셋은 단순하게 article과 highlights(요약문)이 쌍으로 주어집니다. 결국 article에 해당하는 요약문을 얼마나 잘 만들어내는지가 성능 평가에 중요한 요소가 됩니다.
이때 요약 모델의 성능을 평가하기 위해서 ROUGE(Recall-Oriented Understudy for Gisting Evaluation) - N 지표가 활용됩니다. ROUGE - N은 단순하게 N - gram단위로 요약문의 정확도를 비교하는 방법입니다. 얼마나 정확하게 검출했는지만(Recall) 확인하기 때문에 지표만으론 문장이 매끄러운지는 알 수가 없는 단점이 있습니다.
추출적 요약에 대해서 간단히 알아봤으니 해당 테스트에서 높은 성능을 거둔 모델 BERTSum과 MatchSum 에 대해서 알아보겠습니다.
BERTSum(Text Summarization with Pretrained Encoders)
BERT를 Abstractive 및 Extractive Summarization에 효과적이도록 수정된 모델입니다.
기존 BERT에서 얻을 수 있는 segmentation embeddings은 pair 단위의 문장을 처리할 때는 효과적이지만 여러 문장을 함께 고려해야 하는 추출적 요약에선 적합하지 않다고 생각했습니다.
이를 위해 Document-level Encoder를 도입하여 Document 단위의 이해와 문장 Representation을 얻을 수 있었습니다.
최종적으로 Document-level Encoder 상단에 여러 Transformer Layers를 추가하여 Document-level Features을 활용한 추출적 요약 성능 개선에 성공했습니다.
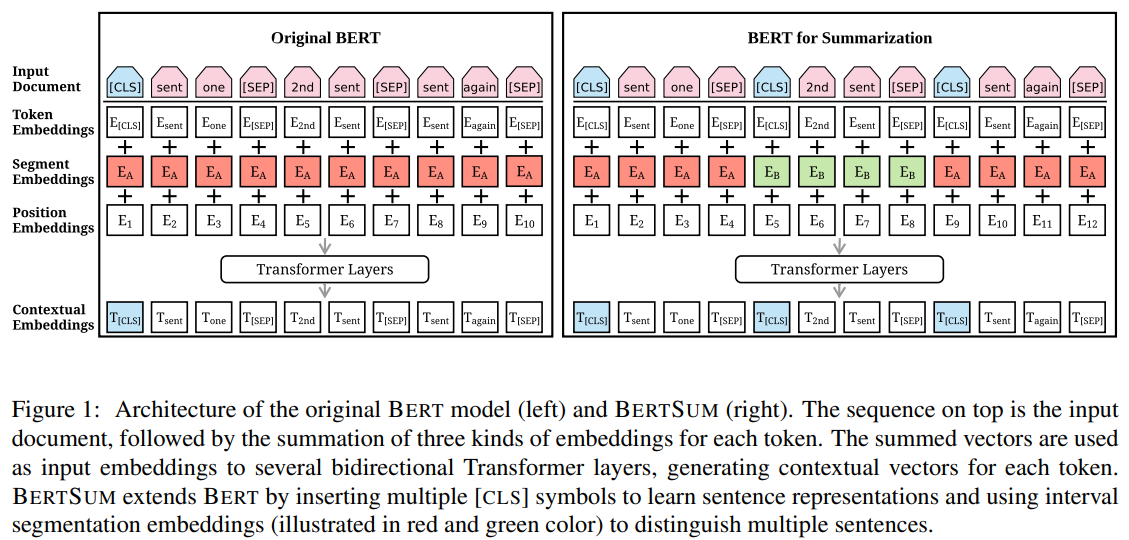
Document-level Encoder의 특징은 다음과 같습니다.
- 각 문장에 대한 Representation을 얻기 위해서 문장이 끝날 때 [CLS] 토큰을 삽입
- multiple - sentences Representation을 위해 Segment Embeddings에 Ea, Eb를 odd/even에 맞춰 할당
- [Single sentecne + Multiple - sentences] Representation => Document level Representations
MatchSum(Extractive Summarization as Text Matching)
기존의 딥러닝 기반 모델들은 각 문장 사이 관계를 매겨(스코어 매겨서 최종 출력)문장을 추출했지만 MatchSum에선 추출식 요약을 Semantic Text Maching문제로 해석하여 접근합니다. 이를 위해 문서와 문서의 추출에서 얻은 후보 요약문들을 Semantic Space상에서 매칭시킵니다.

참고
A Survey of Natural Language Generation
https://medium.com/sciforce/towards-automatic-text-summarization-extractive-methods-e8439cd54715