
Intro
인간이 일상에서 사용하는 언어(자연어)를 컴퓨터에게 이해시키기 위해서 자연어에 담긴 추상적 뜻을 의미있는 숫자들로 바꾸어야 합니다. 자연어를 의미있는 숫자로 바꾸는 작업을 Word Representation(단어 표현)이라고 합니다.
이번 포스팅에선 자연어를 더 잘 표현할 수 있도록 제안된 다양한 방법에 대해서 다뤄보겠습니다.
Word Representation?

단어 표현은 크게 Local, Continuous 표현으로 구분됩니다.
Local 표현의 경우 해당 단어 자체만을 참고하기 때문에 뉘앙스(nuance)을 담지 못하지만 Continuous 표현의 경우 단어 주위를 참고하기 때문에 뉘앙스를 담을 수 있다는 장점이 있습니다. BOW와 Word2Vec이 각각 유명한 Local, Continous 표현입니다.
BOW(Bag of Words)

그림에서 알 수 있듯이 BOW는 문자 그대로 전체 단어들로 이뤄진 가방입니다. 단어를 가방에 넣은 뒤 흔들어주면 순서에 상관없이 빈도수만 고려하면 되게 됩니다.
이러한 원리로 유니크한 단어별로 고유한 인덱스를 부여한 뒤 등장 횟수를 각 인덱스별 값으로 할당합니다.
만약 비슷한 문장에선 같은 단어들이 나온다는 가정이 만족된다면 BOW 표현에서도 문장간 유사도 비교가 가능합니다. BOW 방식으로 문장을 표현하면 다음과 같습니다.
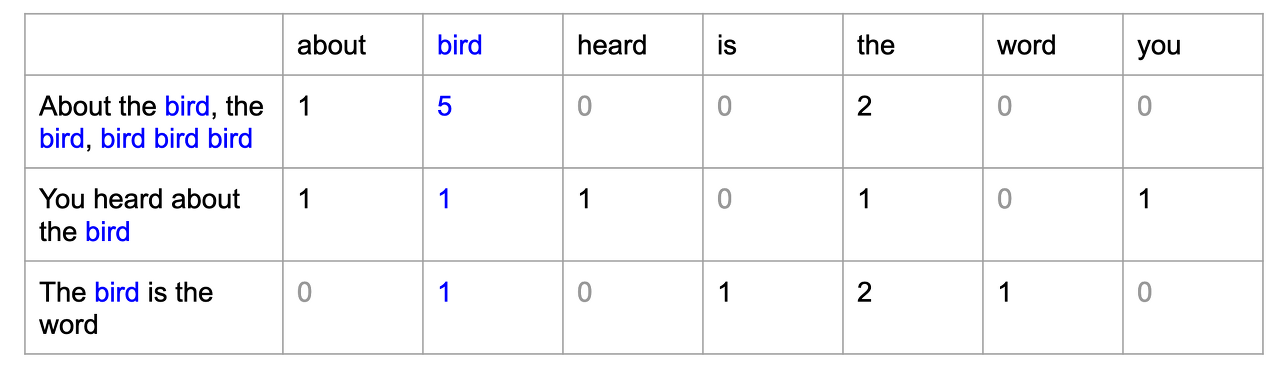
TF-IDF
BOW에선 단어의 빈도수만 고려해 문장을 표현하게 되는데, 이 경우 각 단어가 가진 중요도를 반영하지 않는 문제가 발생합니다. 단어의 중요도를 표현하기 위해선 문서 전체에서의 빈도를 고려하는 방법이 존재하는데, 이것이 바로 TF-IDF 방법입니다.
TF-IDF는 단어의 빈도를 통해 중요도를 표현하는 방법으로 만약 하나의 단어가 많은 문장에 출현한다면 특수한 의미를 구별하는 데 영향이 적기 때문에 중요도가 떨어진다는 가정을 가지고 있습니다. 따라서 TF-IDF를 사용한다면 반복적으로 등장하는 영어의 'a'나 'the'는 중요도가 떨어지게 됩니다.
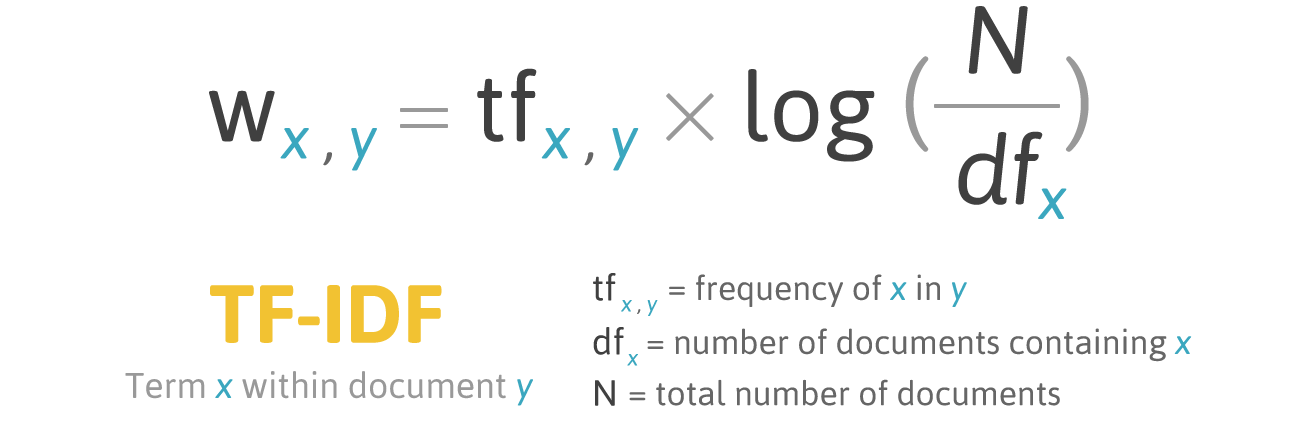
BOW의 순서 구분없이 단어를 분리해서 다루는 방식 그 자체가 단점이 되기도 합니다. 자연어 특성상 텍스트를 구성하고 있는 각각의 단어 뜻과 합쳐졌을 때의 뉘앙스가 항상 동일하진 않기 때문입니다. 따라서 자주 함께 출현하는 N개의 단어를 한 그룹으로 구성하여 하나의 단어(피처)로 생각하여 벡터로 표현하기도 하는데 이것이 N-gram 방법입니다.
Word2Vec(Word Embedding)
Word Embedding(워드 임베딩) 이란 각 단어를 저차원 공간상의 dense vector에 투영시키는 것입니다. 이때 투영을 통해 비슷한 단어는 저차원 공간 상에서 가까운 곳에 놓이다는 가정 하에 진행됩니다. 동일한 K 차원(일반적으로 K = 50 ~ 300 차원)상에 놓인 단어들은 딥러닝 모델을 통해 가중치를 수정해나가는데 잘 훈련된 임베딩 벡터의 경우 실제로 저차원 공간 상에서 인접한 곳에 위치하게 됩니다.
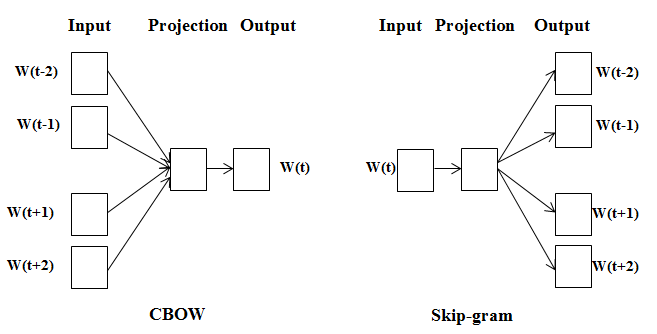
Word2Vec은 워드 임베딩을 학습하기 위해서 많이 사용되는 알고리즘입니다.
앞서 언급했듯이 Word2Vec은 Continuous 표현 방법이기 때문에 주위 단어를 참고해 현재의 단어를 표현합니다. CBOW(Continuous BOW)는 주변에 출현한 단어들에 기반해 현재 단어의 생성 확률을 예측하는 방법입니다. 반면 Skip-gram은 현재 단어에 기반해 위, 아래에 있는 각 단어의 생성 확률을 예측합니다. CBOW와 Skip-gram은 Input, Hidden, Ouput layer를 모두 갖춘 얕은 신경망 모델입니다.
참고 자료 :
데이터 과학자와 데이터 엔지니어를 위한 인터뷰 문답집
https://wikidocs.net/book/2155
https://hleecaster.com/nlp-bag-of-words-concept/
https://ai.stackexchange.com/questions/18634/what-are-the-main-differences-between-skip-gram-and-continuous-bag-of-words
https://dreamgonfly.github.io/blog/word2vec-explained/