
Data Collection
우선, 12억 파라미터로 이뤄진 초기 모델을 구성했다. 이때 330만 개 텍스트-이미지 쌍을 가진 Conceptual Captions 데이터셋을 활용했다.
최종 모델은 파라미터 수가 120억 개로, 이에 따라 Coceptual Captions 외에도 YFCC100M, 위키 피디아에서 얻은 텍스트-이미지 쌍을 추가해 데이터셋을 구성했다.
최종적으로 2억 5천만개의 text-image 쌍을 활용했다. 이때, 데이터 구성 과정에 활용한 필터링 방식은 Conceptual Captions에서 사용한 방식과 동일하다.
Conceptual Captions에서 어떤 방식을 활용 했는 지는 아래 링크를 통해서 확인할 수 있다.
[논문 리뷰] Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text DatasetFor Automatic Image Captioning
MS-COCO의 문제점 COCO 데이터셋엔 그림은 없고, 사진만 있는 등 다양성이 떨어진다. 따라서 데이터가 high correlation을 가지게 된다. 이로인해 아이 사진에 대한 예측 결과를 확인하면 보이지 않는 사
only-wanna.tistory.com
데이터 구성 과정에서 MS COCO의 일부 이미지 데이터가 YFCC100M에 존재하기 때문에, COCO를 활용한 zero-shot 성능 평가에 영향을 줄 수도 있다. 이를 확인하기 위해서 겹치는 COCO 이미지를 제거한 경우, 그대로 활용한 경우의 두 성능을 확인했는데 별 차이는 없었다.
Mixed-Precision Training
GPU 메모리를 아끼고, throughput을 늘리기 위해서, 대부분의 파라미터와 Adam의 moments, activation 값들은 16-bit 정밀도를 활용해 저장했다. 추가로 resblocks 내 activations 값을 일부만 저장하고, 나머지는 역전파 과정 때 다시 계산하는 방법인 activation(gradient) checkpointing도 활용했다.
image에 대한 logits 값과 gains, biases, embeddings, unembeddings과 그에 대한 gradients, Adam moments 값의 경우엔 32-bit 정밀도를 활용해 저장했다. 16-bit 정밀도가 정말 도움되는 부분에만 적용한 것이다.
실제로 embeddings과 logits 값이 16-bit인 경우 훈련이 잘 되지 않았다고 한다!
- Gradient Checkpointing이 무엇이고, 왜 활용하는지는, 아래 링크를 통해서 확인할 수 있다!
Gradient checkpointing이란
GitHub - cybertronai/gradient-checkpointing: Make huge neural nets fit in memory Make huge neural nets fit in memory. Contribute to cybertronai/gradient-checkpointing development by creating an acco..
only-wanna.tistory.com
최종적으로 16-bit 정밀도로 안정적인 gradient를 유지시키며 10억개가 넘는 파라미터를 가진 모델을 훈련하기 위해서는 underflow를 해결하는 것이 중요했다. 실제로, 레이어가 깊어질 수록 gradient가 점점 줄어들어 16-bit 정밀도로 표현할 수 있는 exponent 이하로 떨어지게 돼 0으로 수렴하는 underflow가 발생하는 것이 문제였다.

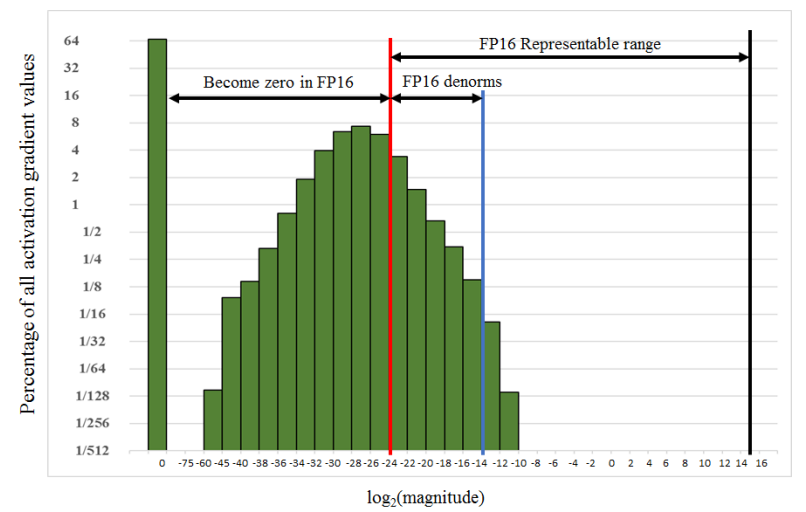
underflow를 방지하기 위해선 scaling을 통해서 16-bit 정밀도가 표현 가능한 값으로 범위를 바꿔주는 방법도 존재한다.
하지만 scaling을 하더라도 V100 GPU의 exponent 범위는 text-to-image 모델을 표현하기엔 부족했다.
이를 해결하기 위해서 각 resblock 별로 gradient scaling을 진행했다.
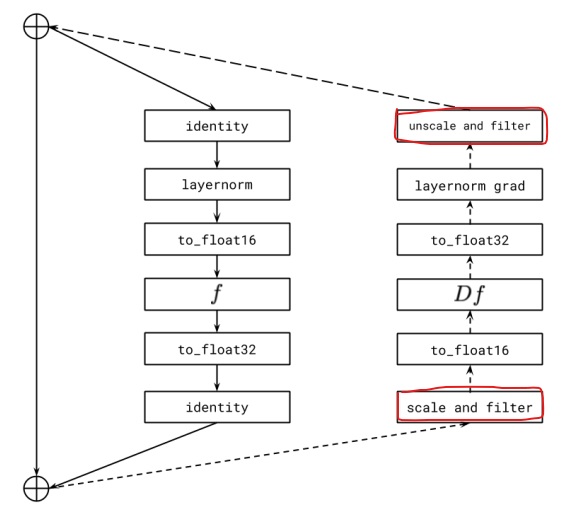
per-resblock gradient scaling에선 각 block 별로 gradient scaling을 진행한다.
실제로 각 resblock 별로 gradient(scaling 전)을 확인해보면 값의 범위가 모두 다름을 확인할 수 있고, 이는 per-resblock gradient scaling이 효과가 있는 이유를 보여준다.
block 단위 처리는 block에서 역전파가 시작되는 순간에 scaling을 하여 overflow를 방지하고, block이 끝나면 다시 unscaling 해준다. 이때, Inf, NaN의 값의 경우 다른 block에 underflow를 유발시키기 때문에 0으로 변경한다.
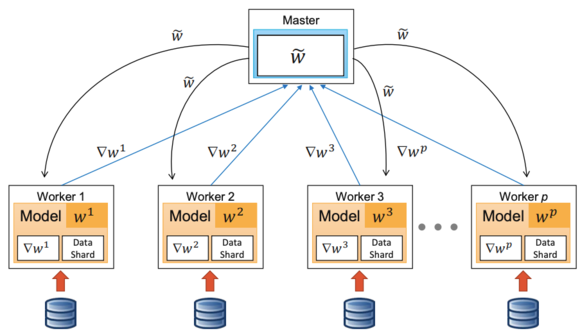
DALL-E 모델을 훈련할 때는 여러 GPU로 구성된 머신(노드)들을 묶고 Data parallel 방법으로 훈련을 진행한다.
이 경우, 최종 gradient 값을 구하는 과정에서 각 노드에서 구한 gradient 값을 평균내야 한다.
이때, gradient가 16-bit 정밀도로 계산되기 때문에 노드 수 M이 크면 나누는 과정에서 underflow가 발생하게 된다.
이러한 문제점을 피하기 위해서 16-bit 정밀도로 연산이 이뤄지기 전에 M 값을 미리 나누고, 합칠 때는 M을 곱하는 방식을 활용했다. 이렇게 되면 16-bit 정밀도의 정확도를 올리기 위해서 M만큼 scaling을 해주는 것과 같은 역할을 하게 된다.
Distributed Optimization
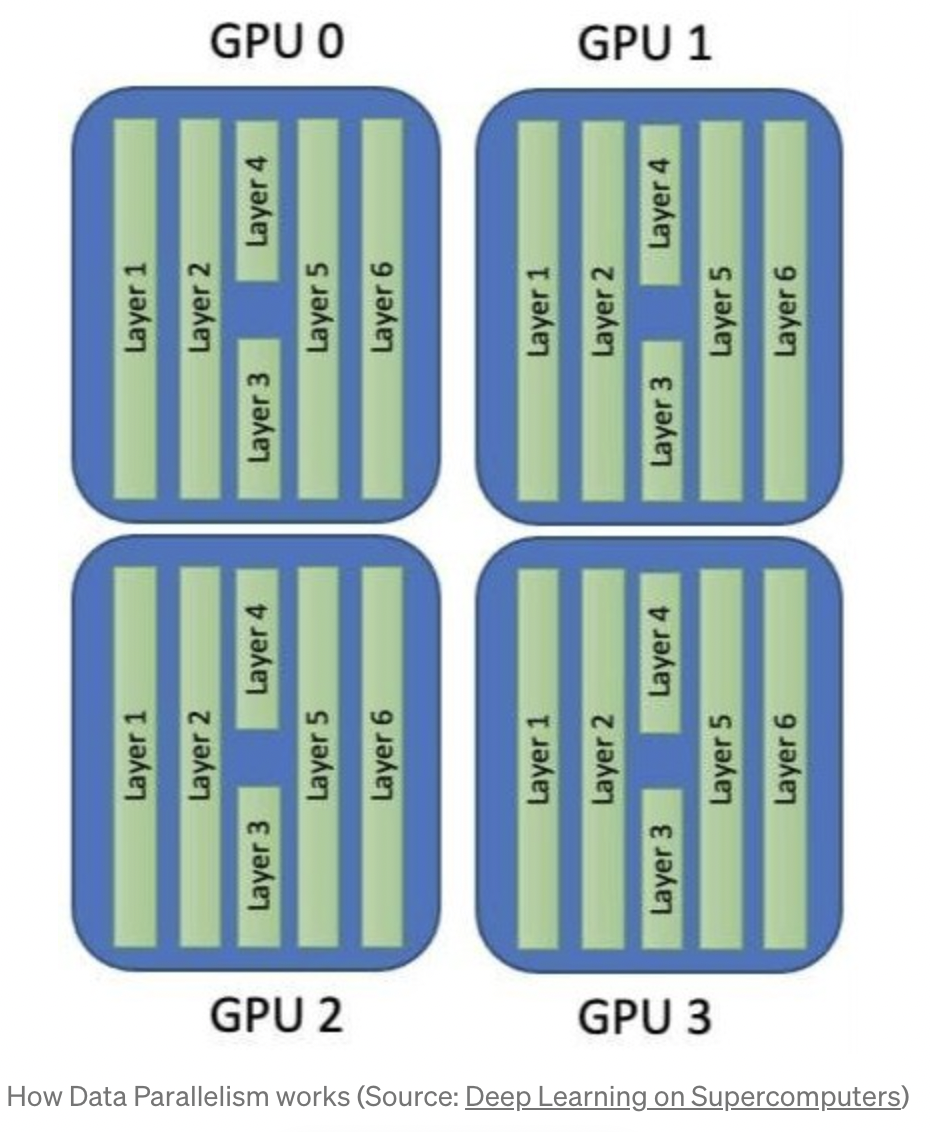
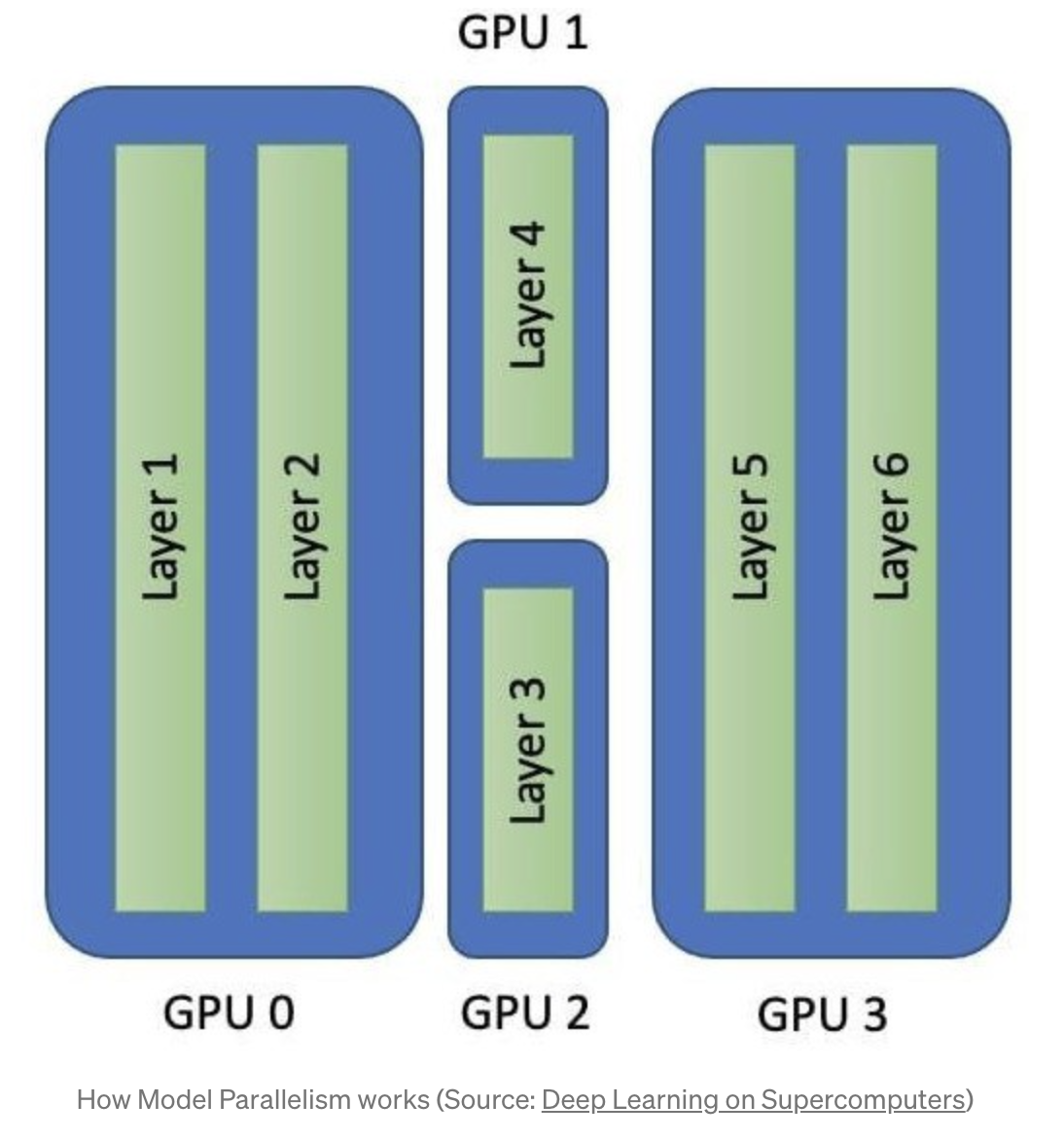
다중 GPU를 분산 학습에 활용하는 방법은 Model parallel(MP), Data parallel(DP) 두가지 방법이 있다.
MP는 layer를 분리해서 처리하기 때문에, 메모리 사용량을 줄일 수 있다는 장점이 있다.
다만 최적의 MP 조합을 설계하는 것이 어렵다는 단점이 있다.
DP의 경우는 데이터를 N개의 GPU에 나눠서 입력하고 각각의 GPU 마다 모델 가중치를 계산 후 나중에 평균내어 활용한다. 이를 통해 여러 데이터를 빠르게 처리할 수 있지만 메모리 사용량은 줄어들지 않는다는 단점이 있다.
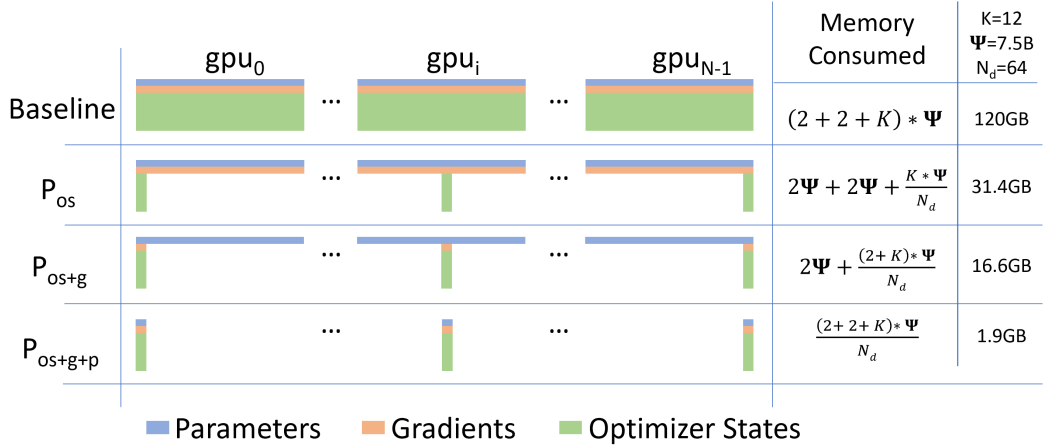
DALL-E는 많은 데이터를 활용하기 때문에 DP가 필요하지만, 16-bit 정밀도를 활용하더라도 모델은 24GB의 GPU 메모리 용량을 요구한다. 훈련에 사용한 V100의 GPU 메모리가 16GB이기 때문에 이를 해결하는 것이 필요했다.
해결하기 위해 DP의 속도와, MP의 메모리 효율을 모두 고려한, ZeRO에서 제시된 parameter sharding(partitioning)기법을 활용했다.
자세한 parameter sharding 과정은 더보기를 통해서 확인할 수 있고, 링크를 참고해도 된다.


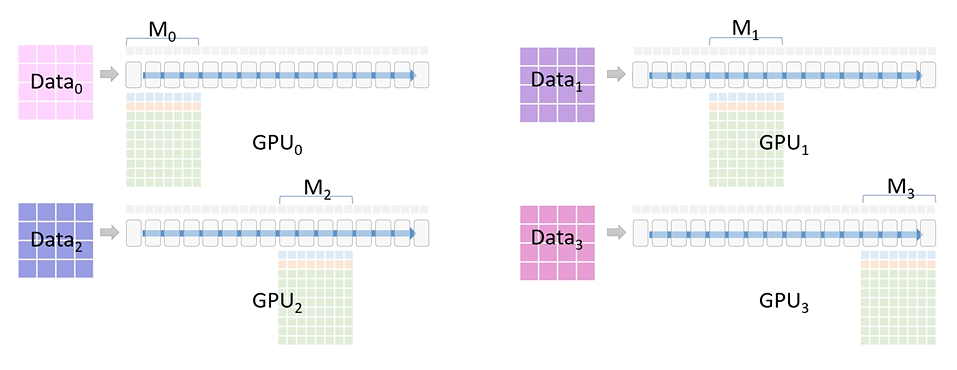
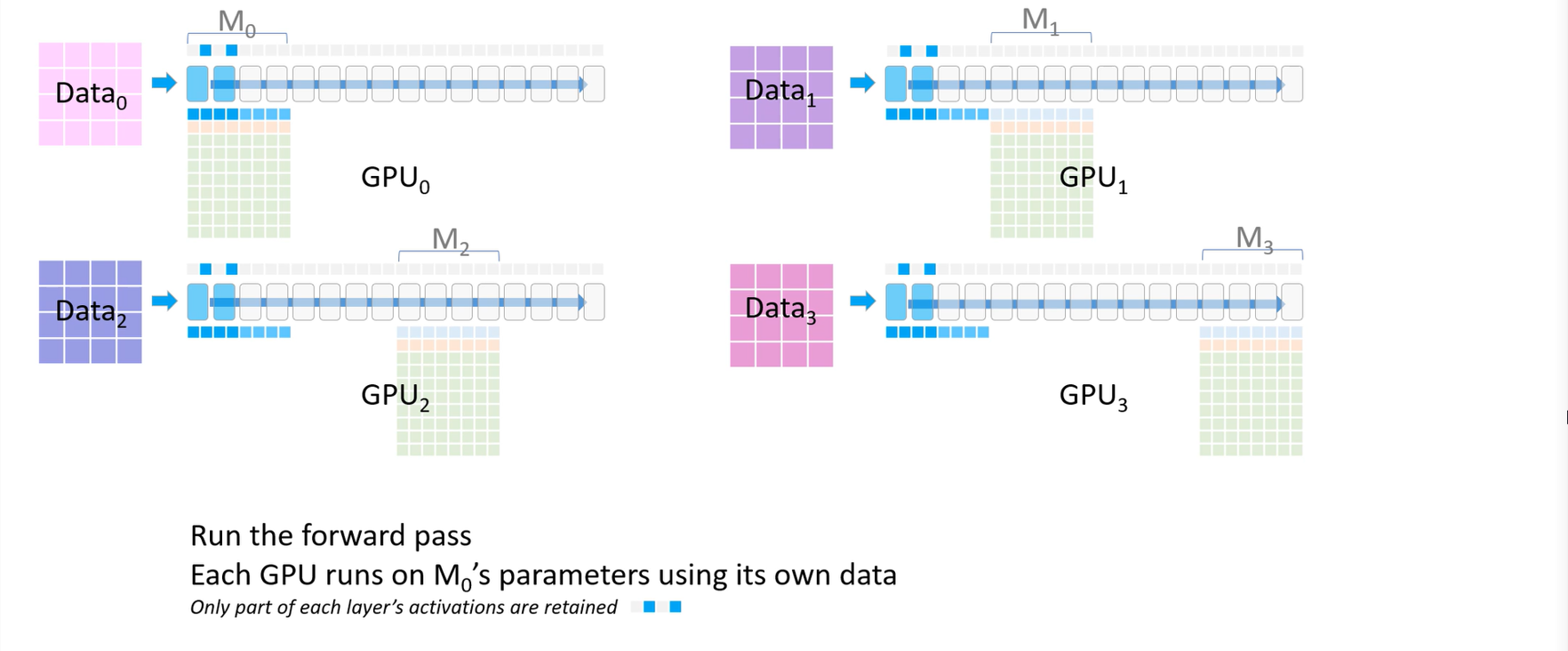
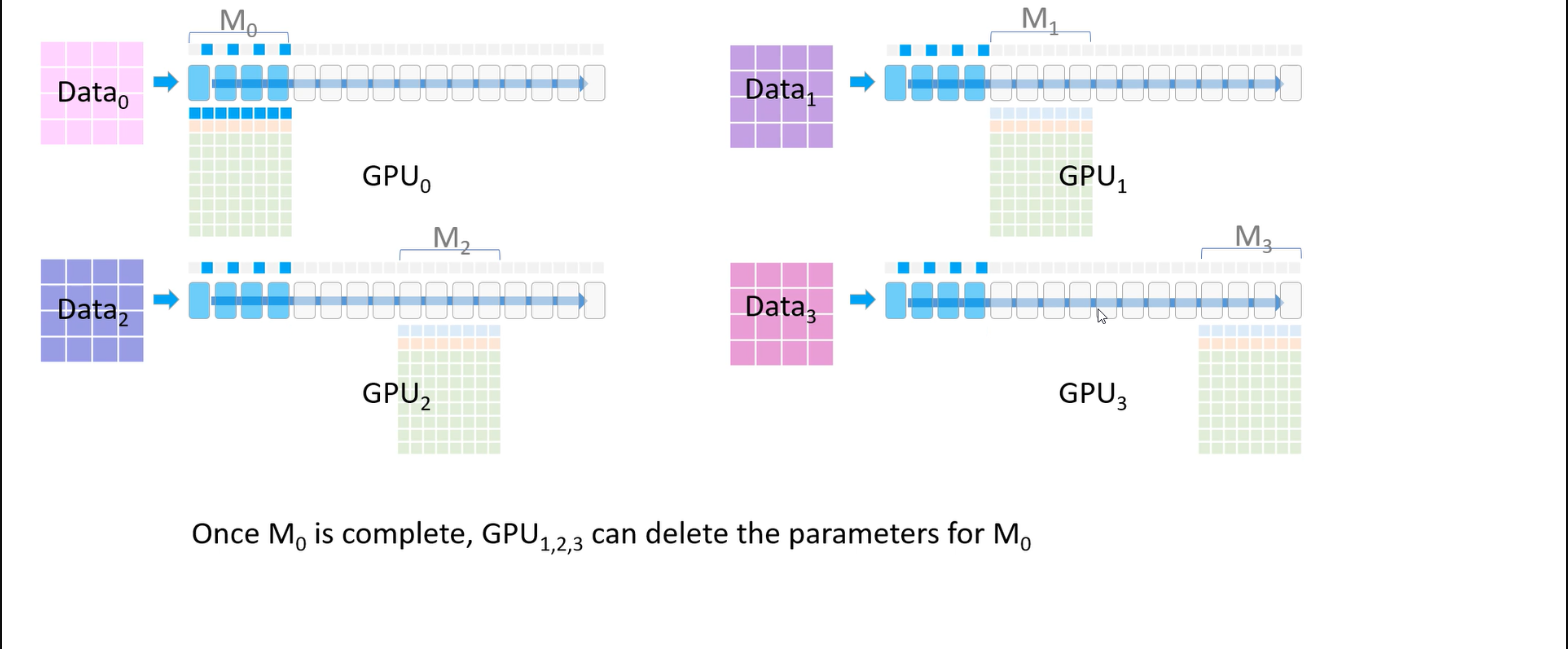
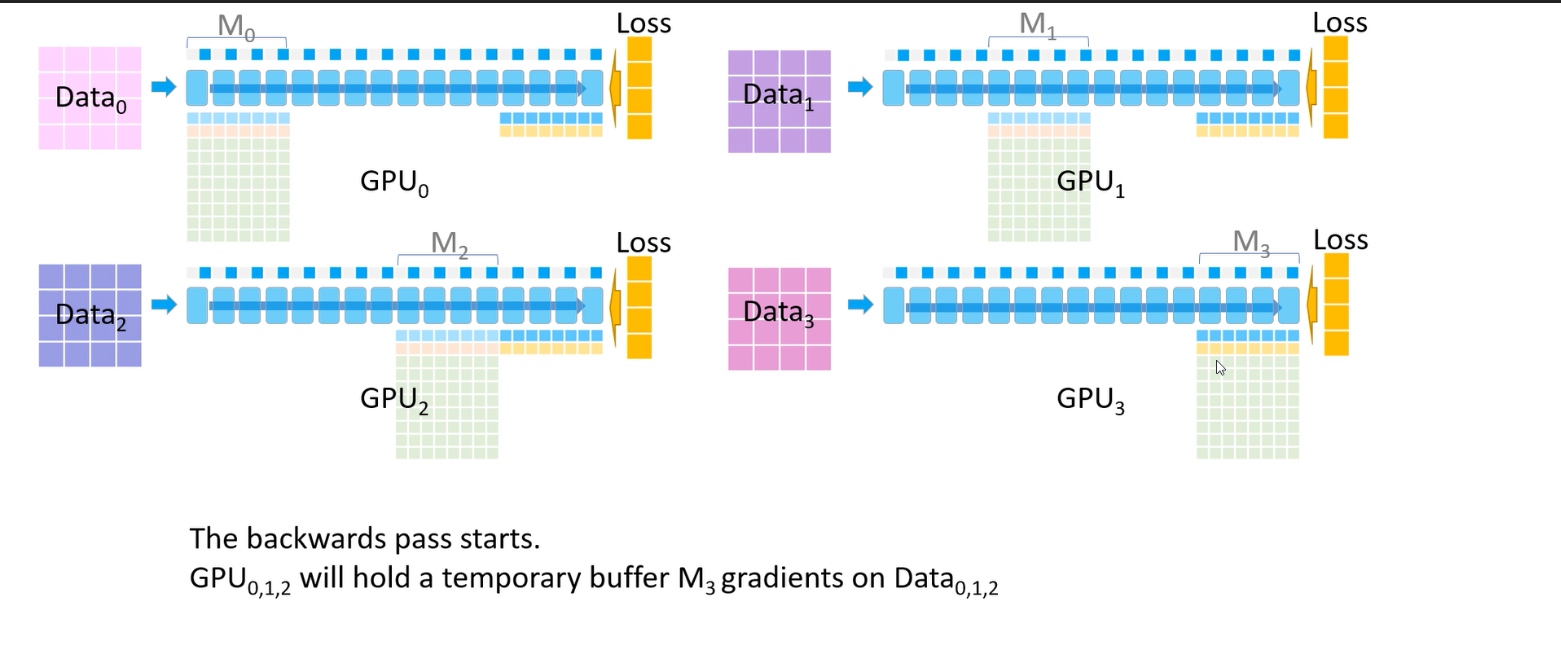
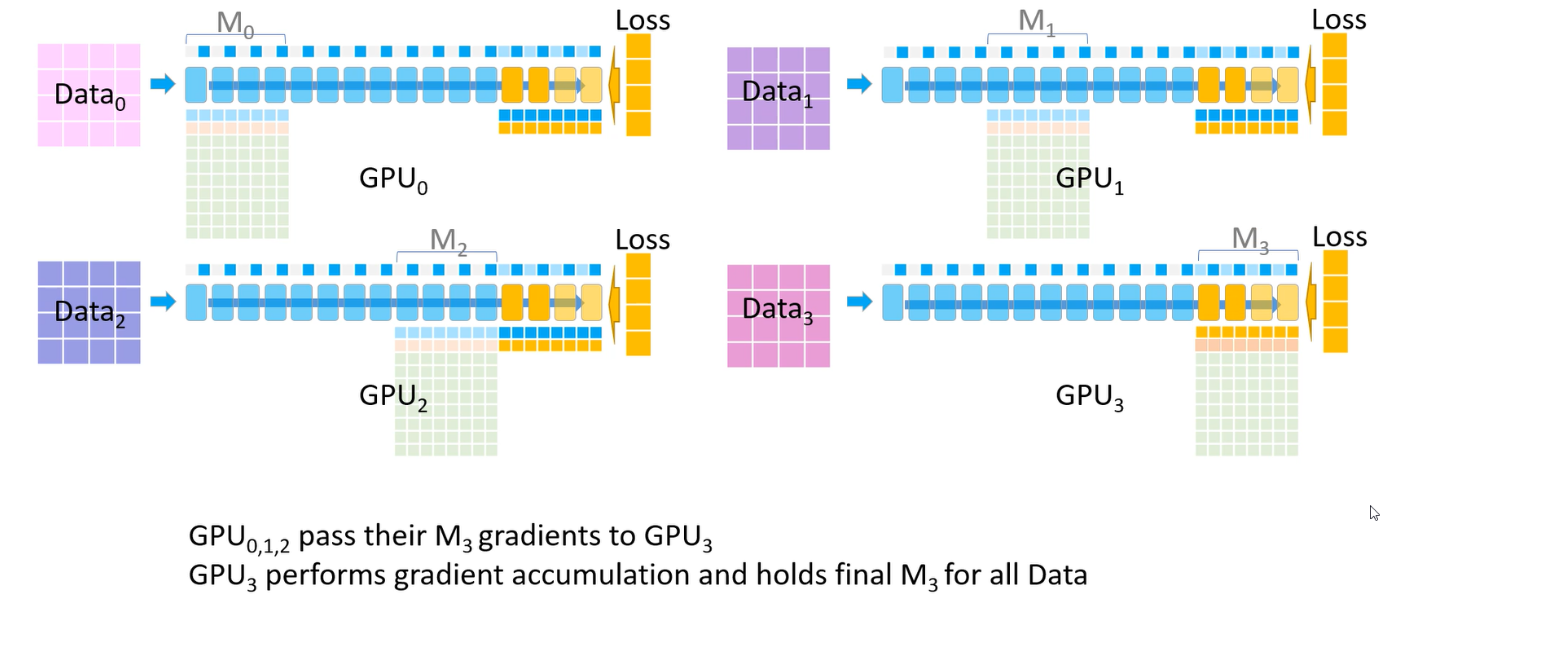
parameter sharding 과정을 통해 결국 각 GPU는 $M_i$의 gradient 평균 값만 저장하게 된다.
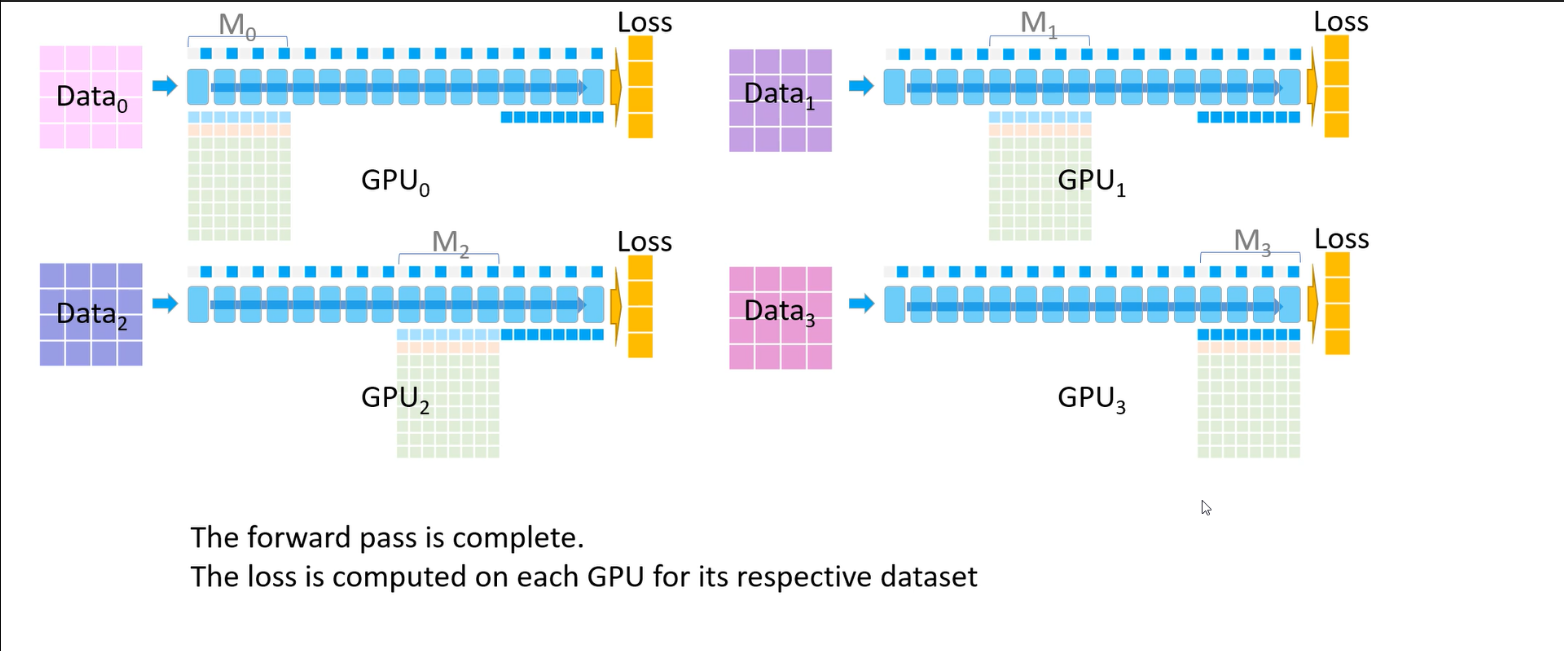
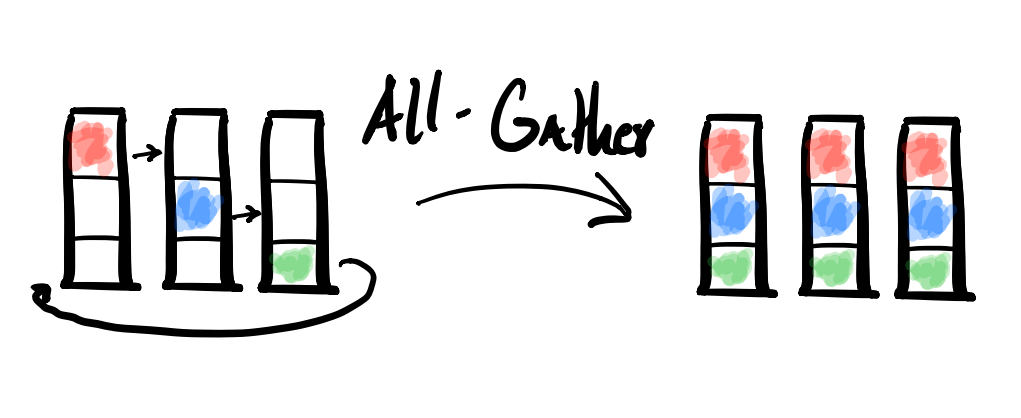
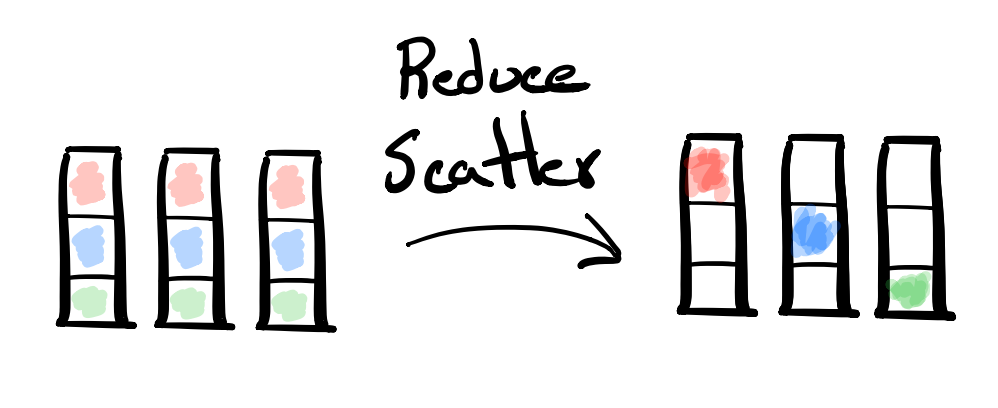
순전파 과정에서 각 GPU의 파라미터를 전달 받아 활용하는 작업은 All-Gather라고 하며 (만약, 전달받은 파라미터를 제거하지 않는다면 결국 모든 데이터를 가지게 된다.), 최종적으로 gradient를 평균 내 각 GPU에 저장하는 것은 Reduce-Scatter라고 한다.
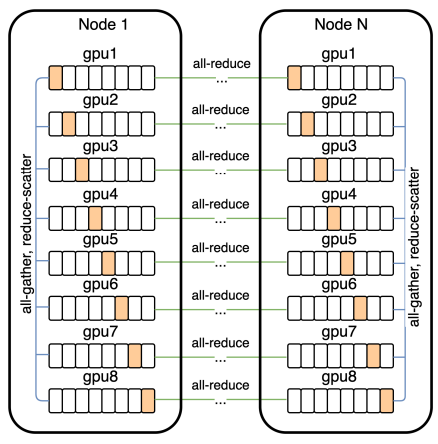
이후엔, 각각 따로 구했던 파라미터 값을 다시 평균내서 사용하는 All-Reduce 작업을 거쳐야 한다.
All-Reduce의 경우 노드 사이 통신이 필요하다.
따라서 네트워크 대역폭이 상대적으로 낮아 병목 현상이 발생한다는 문제가 생긴다.
이를 해결하기 위해서 PowerSGD라는 low-rank factorization을 활용해 값을 압축시켜서 전달한다.
PowerSGD를 실제로 어떻게 활용했는지도 논문에 자세히 언급하고 있는데, PQ로의 행렬 분해를 잘 하려고 여러 가지를 고려한 것으로 보인다. PowerSGD의 특징은 다음과 같다.
- Gain, bias, embedding, unembedding을 제외한 모든 파라미터에 대한 gradient는 PowerSGD로 gradient 압축 수행
gain, bias, embedding, unembedding 값은 32-bit 정밀도로 표현했고, 압축도 하지 않았다.
- 85% compression rate 달성
- Backpropagation 과정에서 gradient를 error buffer로 축적함으로써 개별적인 buffer를 할당하는 방법 대비 메모리를 절약
- error buffer를 0으로 만드는 인스턴스 최소화 (mixed-precision backprop에서 생기는 nonfinite 값 혹은 체크포인트에서 모델을 재시작할 때 등)
- Gram-Schmidt 대신 Householder orthogonalization을 사용함으로써 수치적인 안정성을 개선했다.
Sample Generation

모델 작동 방법, 데이터 구성, 훈련 방법에 대해서 알았으니 이제 MS COCO의 텍스트를 입력 받아 이미지를 생성할 일만 남았다. 생성된 이미지들은 CLIP을 활용해 이미지-텍스트 사이 유사도를 구하고, 그중에서 상위 Rank된 이미지를 활용한다. N이 커질수록 텍스트에 더 가까운 이미지가 생성됨을 확인할 수 있다.
Quantitative Results
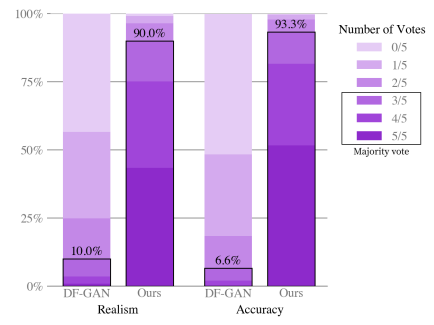
DALL-E는 기존 GAN 기반 모델과 비교 했을 때 정량, 정성적으로 좋은 결과를 얻었다.
사람들에게 어떤 그림이 더 진짜 같은지, 더 잘 묘사한 거 같은 지 물었을 때 90% 이상의 선택을 받았고, Validation 결과와 비교했을 때, 가장 비슷한 이미지가 DALL-E에서 생성됐다.

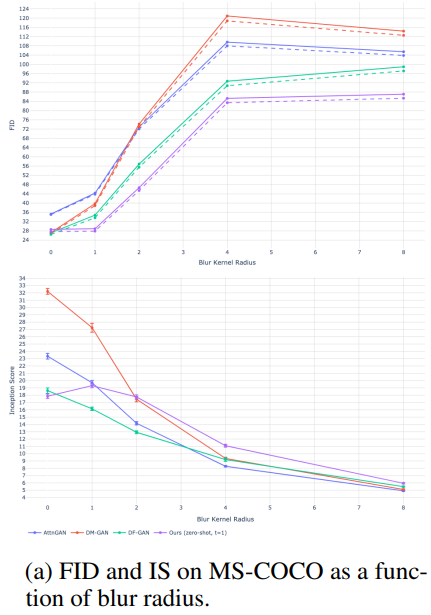
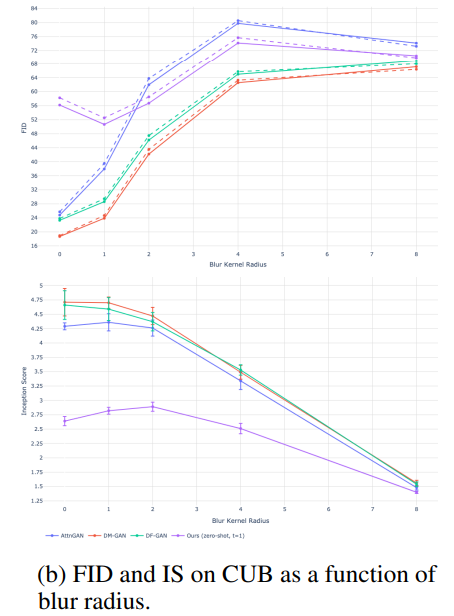
MS COCO 데이터에선, FID, IS 스코어 모두 좋은 결과를 얻었다.
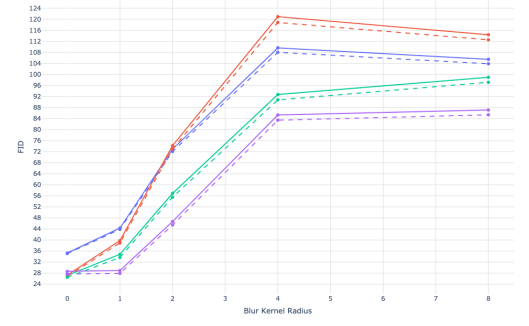
모델링 과정에서 low-frequency에 집중하게 만들어 Gaussian Blur에 취약할 수도 있었지만, 블러 적용 후에도 좋은 성능을 거둘 수 있었다. CUB 데이터에 대해선 좋지 않은 결과를 얻었는데, 이는 CUB가 새라는 도메인에 집중한 데이터이기 때문에 zero-shot으론 온전히 표현하기 어려웠음을 의미한다.

Qualitative Findings
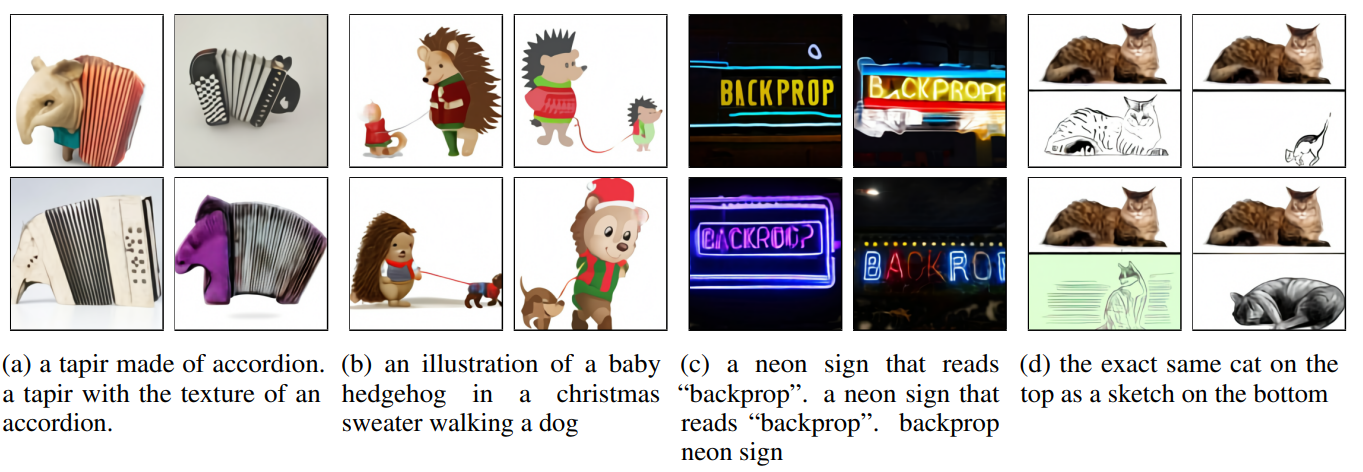
예상치 못한 좋은 결과를 얻을 수 있었다.
- 추상적 문장을 그림으로 표현할 수 있다. ex) 아코디언으로 만들어진 테이퍼
- 문장 내 상황들을 복합적으로 표현할 수 있다. ex) [ic]크리스마스 스웨터를 입은 고슴도치[/ic]가 [ic]개를 산책 시킨다.[/ic]
- image-to-image translation이 가능하다. ex) 네온 사인 색칠, 고양이 스케치

Conclusion
데이터 많이 쓰면 일반화 잘돼서 zero-shot도 잘되고, Qualitive findings 처럼 신기한 결과도 얻을 수 있다. 대규모 데이터는 신이다.
참고
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models